R中的预测:一个人员分析工具

过去6个月,我们比以往任何时候都更强调了解未来的重要性。在本文中,我们将进一步了解预测。预测可以应用于一系列与人力资源相关的主题。我们将具体研究如何在R中部署预测模型,并以一个关于术语“人员分析”日益流行的示例分析作为结束。
目标是知道接下来会发生什么……
预测有不同的形式和大小。有很多监督式机器学习可以生成结果预测的算法,例如飞行风险、安全事件、绩效和参与结果以及人员选择。这些例子代表了非常流行的“预测分析”领域。
然而,在预测领域中一个不太主流的主题是“预测”——通常被称为时间序列分析。简而言之,预测需要一段时间内的价值(例如,120天内股票的收盘价)来预测未来可能的价值。
预测分析和预测之间的主要区别在于所使用的数据。一般来说,预测依赖于历史数据和其中确定的模式来预测未来的价值。
一个与人力资源相关的例子是使用业务或地理上的历史流失率来预测未来的流失率。相比之下,预测分析使用各种额外的变量,如公司绩效指标、经济指标、就业数据等,来预测未来的人员流动率。根据用例,这两种方法都有时间和地点。
在本文中,我们将重点介绍R生态系统中的一个新库ModelTime.ModelTime允许在使用一个整洁的框架的同时快速轻松地应用多个预测模型(对于那些不熟悉R的人来说,不用担心这个)。
相关(免费)资源!继续往下读↓
51人力资源指标备忘单
数据驱动的人力资源从实施相关的人力资源指标开始。下载51个人力资源指标的免费小抄
为了说明使用ModelTime的便便性,我们使用谷歌Trends数据(包括代码)预测了People Analytics领域未来的兴趣水平。从那里,我们将讨论在人力资源背景下预测供应和需求的潜在应用。
数据收集
我们将在示例中使用的时间序列数据直接来自谷歌Trends。谷歌趋势是一个在线工具,使用户能够在谷歌搜索,谷歌新闻,谷歌图像,谷歌购物和YouTube内发现搜索行为的趋势。
为此,用户必须指定以下内容:
- 一个搜索词(最多四个额外的比较搜索词是可选的),
- 地理位置(即执行谷歌搜索的位置),
- 一个时间段,和
- 谷歌来源的搜索(例如,网络搜索,图片搜索,新闻搜索,谷歌购物,或YouTube搜索)。
需要注意的是,返回的搜索数据并不代表实际的搜索量,而是一个从0到100的标准化索引。返回的值表示所选时间段内相对于最高搜索兴趣的搜索兴趣。数值为100表示该术语的最高受欢迎程度。值为50意味着该术语在该时间点的受欢迎程度是原来的一半。0分表示这一项没有足够的数据。
#库
图书馆(gtrendsR)
图书馆(tidymodels)
图书馆(modeltime)
图书馆(tidyverse)
图书馆(timetk)
图书馆(lubridate)
图书馆(flextable)#谷歌趋势参数
Search_term <- "people analytics"
位置<- ""#全球
时间<- "2010-01-01 2020-08-01"#使用日期格式“Y-m-d Y-m-d”
Gprop <- "web"#谷歌趋势数据请求
gtrends_result_list <- gtrendsR . result_list:: gtrends(
关键词= search_term,
Geo =位置,
时间=时间,
Gprop = Gprop
)#数据清理
Gtrends_search_tbl <- gtrends_result_list . txt% > %
摘下(“interest_over_time”)% > %
as_tibble()% > %
选择(日期、冲击)% > %
变异(日期=ymd(日期)% > %
重命名(value = hits)
#谷歌趋势数据可视化
gtrends_search_tbl% > %
timetk:: plot_time_series(日期、价值)
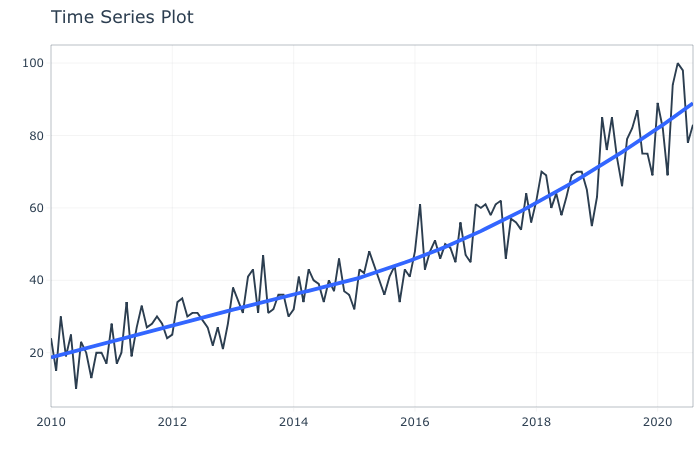
我们可以从可视化中看到(去这里从2010年1月到2020年8月,“人物分析”一词在谷歌网络搜索中呈上升趋势。使用黄土平滑器(即,一种非参数技术,试图找到最佳拟合曲线,而不假设数据遵循特定分布)建立的蓝色趋势线说明了兴趣的持续上升。原始数据还表明,“人物分析”的谷歌搜索词在2020年6月达到顶峰,这也许并不令人意外。
这一高峰可能与2019冠状病毒病的影响有关,特别是要求各组织在此期间就人事主题提交有针对性的特别报告。无论如何,未来的人物分析似乎越来越重要。
建模
让我们进入预测!使用ModelTime所采用的流程如下:
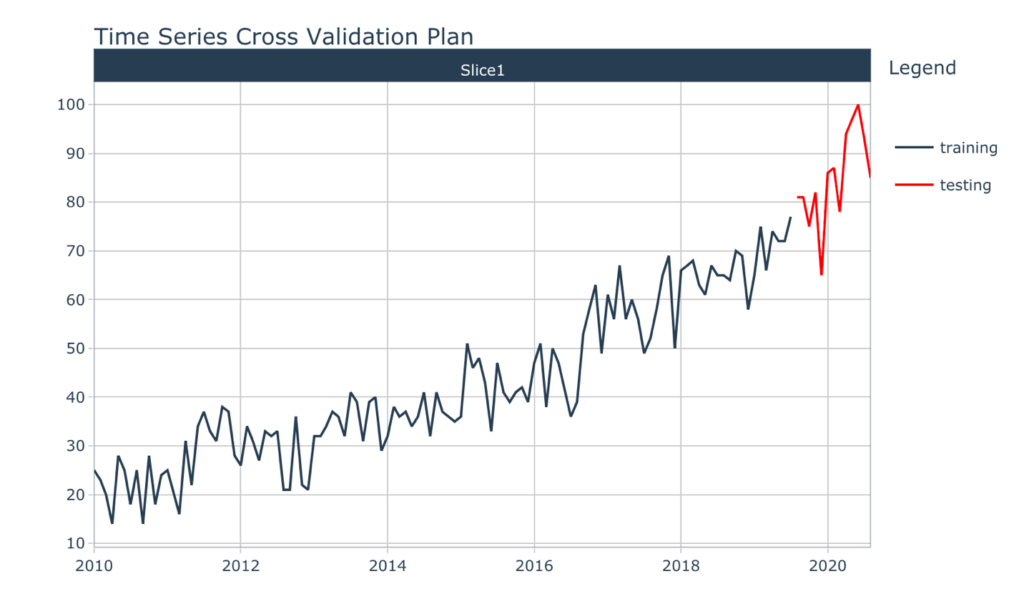
- 我们将数据集分为“训练”和“测试”数据集。培训数据代表2010年1月至2019年1月的数据,而测试数据代表过去18个月的数据(即2019年2月至2020年8月)。这种分割的视觉表现形式如下图4所示。
- 训练数据被用于使用几个不同的模型生成18个月的预测。在本文中,我们选择了以下模型:指数平滑、ARIMA、ARIMA Boost、Prophet和Prophet Boost。
- 然后将生成的预测与测试数据(即实际数据)进行比较,以确定不同模型的准确性。
- 然后,根据不同模型的准确性,将一个或多个模型应用于整个数据集(即2010年1月至2020年8月),以提供到2021年的预测。

下面是步骤1到步骤3的R代码。
#培训/测试
K <- 18
no_of_months < -lubridate::间隔(基础::分钟(gtrends_search_tbl美元日期),
基地::马克斯(gtrends_search_tbl美元日期)% / %
基地::月(1)
Prop <- (no_of_months .-k)/no_of_months
#从训练集中移除过去18个月(即k)的数据,以便我们可以确定模型的准确性
分割<- rsample:: initial_time_split(gtrends_search_tbl,道具=道具)
#可视化训练数据(即黑线)和测试数据(即红线)
分裂% > %
tk_time_series_cv_plan()% > %
plot_time_series_cv_plan(日期、价值)
#建模
指数平滑
Model_fit_ets <- modeltime:: exp_smoothing()% > %
欧洲防风草:: set_engine(engine = "ets")% > %
欧洲防风草::适合(值~日期,数据=培训(分裂))
频率= 1年12次观测
# ARIMA
Model_fit_arima <- modeltime:: arima_reg()% > %
欧洲防风草:: set_engine(“auto_arima”)% > %
欧洲防风草::适合(
价值~目前为止,
data =培训(分裂))
频率= 1年12次观测
# ARIMA Boost
Model_fit_arima_boost <- modeltime:: arima_boost()% > %
欧洲防风草:: set_engine(“auto_arima_xgboost”)% > %
欧洲防风草::适合(
价值~日期+as.numeric(日期)+月(date, label = TRUE),
data =培训(分裂))
频率= 1年12次观测
#先知
Model_fit_prophet <- modeltime:: prophet_reg()% > %
欧洲防风草:: set_engine(“先知”)% > %
欧洲防风草::适合(
价值~目前为止,
data =培训(分裂))
#先知增强
Model_fit_prophet_boost <- modeltime:: prophet_boost()% > %
欧洲防风草:: set_engine(“prophet_xgboost”)% > %
欧洲防风草::适合(值~日期+as.numeric(日期)+月(date, label = TRUE),
data =培训(分裂))
#模型时间表
model_tbl < -modeltime_table(
model_fit_ets,
model_fit_arima,
model_fit_arima_boost,
model_fit_prophet,
model_fit_prophet_boost)
使用支撑数据校准模型精度
Calibration_tbl <- model_tbl% > %
modeltime_calibrate(测试(分裂))
calibration_tbl% > %
modeltime_accuracy()% > %
flextable()% > %
大胆的(part = "header")% > %
bg(bg = "#D3D3D3", part = "header")% > %
最适合的()
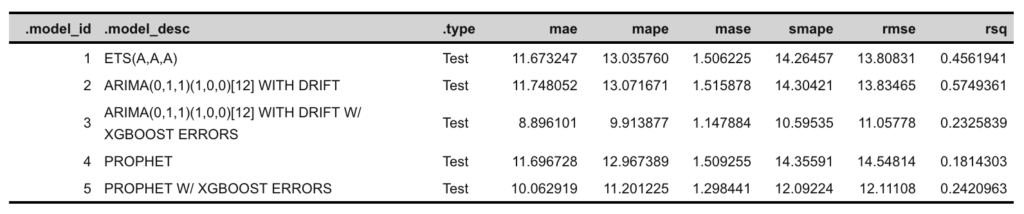
下表说明了在使用Test集评估各自模型的准确性时获得的度量。虽然解释模型及其精度度量超出了本文的范围,但在查看下表时,一个简单的经验法则是,较小的数字表示更好的模型!
我们的模型表明温和的精确度。如果我们简单地看一下“mape”(平均绝对百分比误差)统计数据,我们可以看到最佳模型(3 - ARIMA with XGBoost Errors)显示出与实际数据大约10%的差异,而其余的误差在11% - 13%之间变化。
下图说明了模型相对于实际数据(即我们的测试集)的表现。去这里这张图的互动版本。
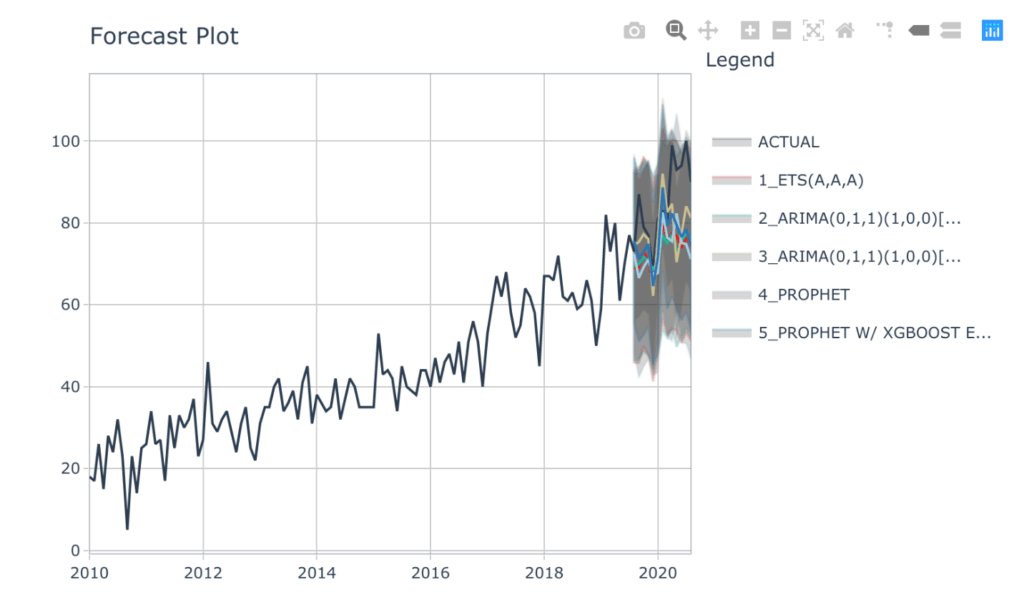
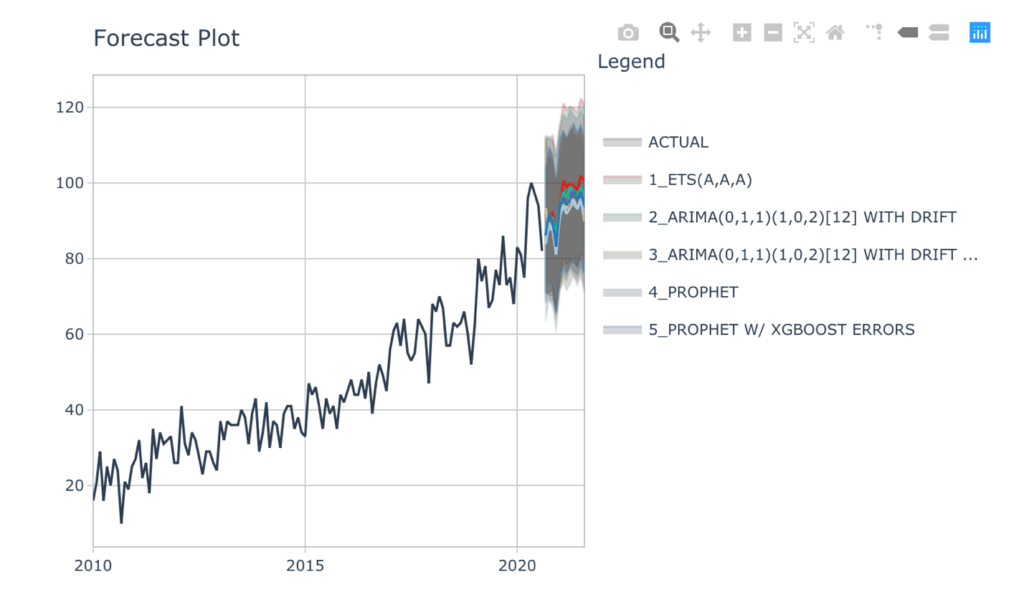
基于这些指标,我们决定采用所有五种模型,对2021年进行预测。然后,我们将对每个月的五个预测取平均值,以创建一个汇总模型。我们可以在下面的代码和交互式可视化中看到,人员分析的持续趋势是随着时间的推移越来越受欢迎。
#用所有数据改装五个模型,以预测12个月(即2020年9月至2021年9月)
Refit_tbl <- calibration_tbl% > %
modeltime_refit(data = gtrends_search_tbl)
Forecast_tbl <- refit_tbl% > %
modeltime_forecast(
H = "1年",
Actual_data = gtrends_search_tbl,
Conf_interval = 0.90)
#绘制到2021年的五个预测
forecast_tbl% > %
plot_modeltime_forecast(.interactive = TRUE)
#海损模型
Mean_forecast_tbl <- forecast_tbl% > %
过滤器(。key! =“实际”)% > %
group_by(。key, .index)% > %
总结(在(value:.conf_hi,意味着))% > %
变异(
.model_id = 6,
.model_desc = "模型的平均值"
)
# *可视化模型平均----
forecast_tbl% > %
过滤器(。key= =“实际”)% > %
bind_rows(mean_forecast_tbl)% > %
plot_modeltime_forecast()
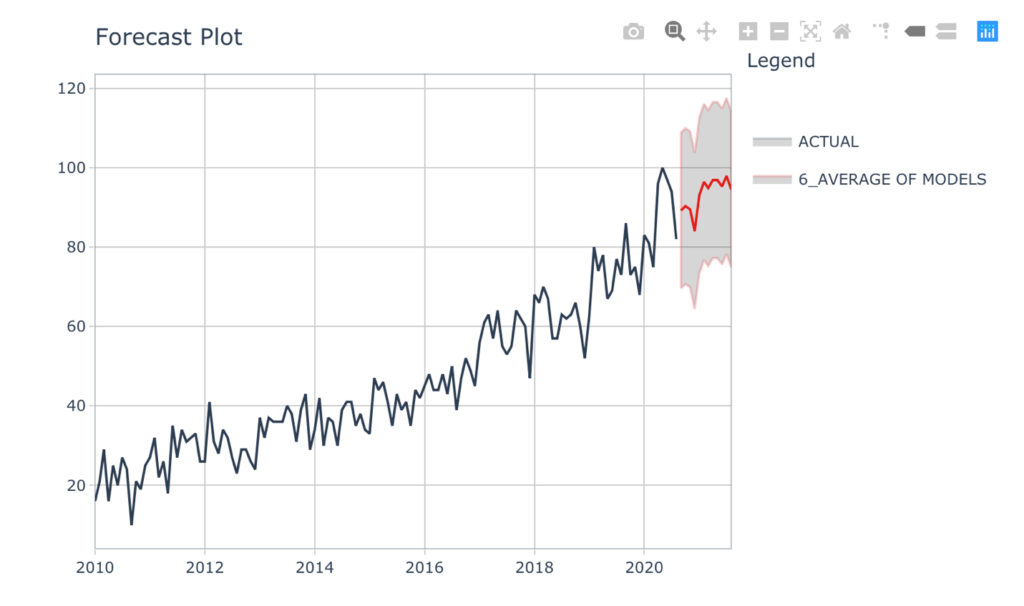
谷歌搜索兴趣在未来12个月的预测似乎继续上升的趋势-未来的人物分析似乎是光明的!对于这个图表的交互式版本,去这里.
人力资源预测的意义
上面的例子说明了分析人员可以很容易地在R中使用时间序列数据进行预测,以便更好地为未来做好准备。此外,自动化模型(即那些自我优化的模型)的使用可以成为预测的一个很好的切入点。R中的ModelTime等技术使用户能够应用许多复杂的预测模型来执行组织内的场景规划。
场景规划不需要只执行一次,然后搁置起来收集灰尘,不管环境条件如何变化。在人力资源领域,预测可以发挥至关重要的作用,但往往没有充分利用的战略活动的一部分,如:
- 劳动力计划
- 未来公司需要更换多少员工?
- 当地的就业市场或大学是否能“培养”出足够的员工来满足组织对毕业生/专业员工的预期需求?
- 在新市场开设新工厂时,当地人口是否足以满足我们的员工要求?
- 人才收购
- 在接下来的2 - 4个季度里,我们可能会招聘多少员工来实现业务目标?
- 在特定地区需要多少人才招聘人员来满足季节性招聘需求(因地区而异!)?
- 外包
- 根据历史上的外包活动,目前的趋势是什么,与该需求相关的财务影响是什么?
- 外包供应商是否能够满足未来的需求?
- 基于外包角色之间的人员流动率,特定业务/地区对入职和培训需求的未来影响是什么?
- 人才管理
- 在近期或中期的未来,我们是否有可能经历人才短缺的工作领域?
- 在未来的2 - 5年内,有多少比例的雇员可能会退休?
- 学习与发展
- 在已确定的未来技能中,未来的要求是什么?
- 财务预算
- 未来人力资源活动的预算要求是什么?
- 与建立人员分析团队相关的未来财务需求是什么?
预测快乐!
致谢:作者想要感谢Matt Dancho在TimeTK和ModelTime开发方面的工作,以及由Matt运行的Learning Labs Pro系列,本文就是基于这个系列。


亚当·麦金农
亚当他是澳大利亚墨尔本Reece集团的人员数据与分析主管。亚当拥有心理学、信息技术、流行病学和金融学等多学科的学术背景,他提倡在工作中提出两个问题:那又怎样?和2。现在怎么办呢?他负责通过统计和机器学习综合与人相关的主题的规模,使组织能够在决策中以员工为中心。
你准备好迎接HR的未来了吗?
在线学习现代和相关的人力资源技能
