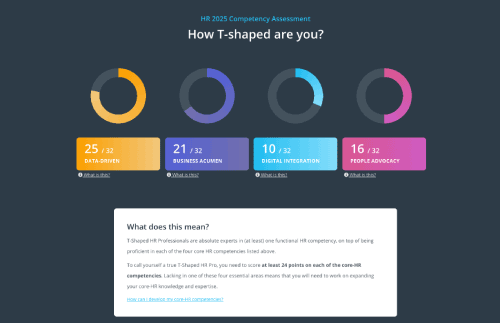
7人力资源数据集的人分析

人力资源数据集很少见。在本文中,我将列出7个在线可用的最佳人力资源数据集。除了数据集,我还将列出数据中的挑战。这可以是一个潜在的分析,或者在数据中寻找一些东西。
我们强烈主张使用数据和统计数据作为达到目的的手段。在分析中,我们希望通过数据和统计来解决业务问题。分析和统计本身并不是目的——除非你想学习如何使用它。这就是我们写这篇文章的目的。
请注意。在本文中,我可能偶尔会使用“predict”这个词。大多数数据集都是横断面的,因此不可能“预测”一个因变量。
现在我们已经完成了手续和免责声明,让我们开始处理HR数据吧!
1.旷工
这个庞大的人力资源数据集中在员工缺勤上。它包含惊人的8335行和13列数据。
数据集包含员工人数和姓名、性别、城市、职位、部门、商店位置、业务单位、部门、年龄、服务年限和缺勤小时数。
相关(免费)资源!继续往下读↓
51人力资源指标备忘单
数据驱动的人力资源从实施相关的人力资源指标开始。下载51个人力资源指标的免费小抄
这个数据集结构整齐。这意味着每个员工都有一条线,缺勤时间被视为每个员工每年缺勤的总时间。
潜在的有趣分析
该数据集适用于识别组织中缺失的部分。这些地区可能需要干预。' absent thour '将被用作因变量。此外,年龄和服务年限也可能与缺勤有关——但如何联系呢?这是你自己的事。
该数据集还可以用作使用决策树或线性模型预测缺勤的练习集。
挑战
这个数据集非常简单。它很大,但在SPSS或Excel等软件中仍然可以管理。在进行分析之前,您可能必须将一些名义变量编码为数值,但除此之外,数据本身并没有太大的挑战。
注意:数据确实需要清理。18岁以下或65岁以上的人都可以从数据集中删除。
下载
此数据集由林登Sundmark,作家做人力资源分析- R示例从业者手册,目的是学习预测缺席的结果。数据集可以下载在这里(镜子).
林登在他的书中详细解释了如何做到这一点。或者,您也可以下载他对该案例的免费描述,其中他在第1部分(使用R)创建决策树之前运行可视化(描述性)分析,在第2部分运行线性回归预测缺位。他书中的相关章节是以这两篇文章为基础的。
2.(更多)旷工
这个人力资源数据集关注的是工作缺席情况。该数据集包含740行和21列的数据。
数据集包含许多雇员id。每一行代表一定数量的缺勤——这意味着一个员工可以有多行。
员工信息包括子女数、工作量、工作距离、交通费、教育程度、身高、体重、身体质量指数(BMI)、旷工时间(以小时为单位)等。其他信息包括季节、缺勤月份、缺勤日和星期几。
该数据集还将缺勤分为21类,即缺勤原因。这些包括不同类型的疾病、先天性功能障碍和怀孕。完整的列表可以在Kaggle上的下载描述中找到。
潜在的有趣分析
这个数据集可以帮助您找到缺席的预测因素。潜在的分析可能是看看BMI和缺勤之间是否存在关联,以及季节、工作量、工作距离和数据集中的其他因素。
挑战
这个数据集的挑战主要在于数据的结构。每个员工都有多条记录。在分析之前,需要将这些数据结合起来。该数据集还使您能够进行纵向研究。
下载
3.人力资源数据集
下一个数据集实际上是一个包含五个不同的小数据表的数据集。该数据集包含一个core_datasheet、一个人力资源数据集、一个生产人员数据集、一个招聘成本数据集和一个工资网格。
由于表是链接的,数据集具有一些有趣的属性。HRDataset_v9.csv文件包含职位,salary_grid.csv文件包含这些职位的工资,production_staff.csv文件包含所有生产函数,包括它们的绩效分数、请求帮助的次数、每日错误率和90天的投诉。
该数据集由Rich Huebner博士和Carla Patalano博士为他们的人力资源管理研究生课程人力资源指标和分析创建。
挑战
其他挑战包括寻找生产人员的次优表现的预测因素(使用其他数据表)。次优性能有多个因变量,包括性能评级、每日错误率和90天投诉。通过将其链接回类似于更一般的HRIS信息的数据集,您可以部署决策树和线性回归模型来预测性能。
另一个数据表的标题是recruiting_cost.csv。这包括在不同招聘渠道上的支出。HRDataset_v9.csv包含雇用源和雇用日期,允许您潜在地计算诸如采购渠道有效性和平均采购渠道成本等指标。
数据表还包含有关活动状态或终止状态的数据,允许您预测终止,并将其与其他数据表中包含的所有其他数据关联起来。
这可能意味着主要的挑战是信息的丰富性。从你提出的一个具体的研究问题开始,然后开始用数据来回答它——否则你会迷失在所有的数据中。
下载
数据集可以下载到Kaggle(镜子).此数据集的代码本可以找到在这里.
4.IBM人力资源分析员工流失和绩效
这个数据集在人物分析领域很有名。当IBM创建一个数据集,使您能够练习减员建模时,您需要注意。该数据集有1470行和35列。
数据集包含年龄、性别、工作满意度、环境满意度、教育领域、工作角色、收入、加班时间、加薪百分比、任期、培训时间、现职年限、关系状态等数据。
通过这些变量,IBM创建了一个相当完整的概述,其中包含了平均HRIS的数据,并结合了完整的敬业度调查。因此,该数据集非常适合预测离职率,或者仅仅是找出留下来和离开的团队之间的差异。
挑战
这个数据集提供了很多可能的分析。其中最有趣的可能是使用决策树或逻辑回归来寻找预测因子。注意,看看罗伯特帕夏的幻灯片为什么你不应该使用逻辑回归来预测流失率之前!
或者,你可以使用更简单的单向方差分析或卡方检验,来找出离职和留任两组员工在工作满意度和是否拥有股票期权等因素上的差异。
下载
最初,该数据集发布在IBM的网站上,但已被删除。数据集仍然可用Kaggle(镜子).注意,在原始IBM文件中有第二个工作表,称为Data Definitions。在Kaggle中,这些数据定义已经包含在文件的描述中。
5.营业额数据由Edward Babushkin设置
爱德华·巴布什金是一位俄罗斯人民分析家和多产作家。通过他的俄语博客,他建立了一个大型的人口必威 官方网站分析从业者社区,并成为东方人口分析的代表人物。
数据集包含性别、年龄、工资类型、出行方式、交通(雇佣来源)、大五人格等信息!
挑战
在他的一篇翻译文章中,他提出了这样一个问题:约翰逊、彼得森还是西多森,哪位员工最有可能留在公司最久?在他的支持文章中,他还展示了如何使用生存分析来预测这一点。
据爱德华说,数据集是真实的——这令人兴奋!至于其他的,数据是相当直接的。唯一需要注意的是,一些术语在从俄语翻译到英语的过程中丢失了。例如,“独立”被翻译为宜人性的反向尺度,“自我控制”是尽责性,“焦虑”是神经质,“novator”代表开放。
下载
您可以下载数据集在这里(镜子)来自爱德华的Dropbox。可以找到包含示例分析的支持文章在这里.
6.工作分类
另一个由Lyndon Sundmark提供的独一无二的数据集可以用于工作分类。职业分类既反映了职业类别,也反映了与薪酬等级相关的信息。当需要适应现有工作结构的新工作被创造出来时,这一点尤其重要。
工作有许多不同的特征,这些特征影响着工作的分类。这些因素包括教育水平、经验、组织影响力、监管水平、财务预算等等。了解了不同工作的这些因素,职业分析师就可以根据工资等级和福利待遇将工作分类。
挑战
Sundmark指出,线性判别分析(LDA)可以用来找到特征的组合,这些特征是许多类对象或事件的特征。使用LDA, Sundmark的作业分类数据集可以用于对现有作业结构中新创建的作业进行分类,为新创建的函数提供指导。
在这个数据集中,有66个工作规格,涵盖11个工资等级。上面提到的所有因素都包括在内,甚至更多。
下载
你可以在这里下载数据集。可以找到一篇描述如何在R中进行分析的支持性文章在这里(镜子).
7.参与调查
最难获得的数据集之一是参与度调查。这有几个原因,最重要的是在这些调查中高度保密和公司敏感信息。
然而,对于那些想要学习的人来说,有一个数据集。在我们的人力资源统计课程中,我们使用了85个人的敬业度数据集,他们都填写了一份敬业度调查。数据集包含绩效评级、职能组等变量,还包括创新行为、多维度敬业度得分、个人主动性、职业管理行为、流动性行为(即离开公司的可能性)、组织和专业承诺等。

课程截图,左边是数据集。数据用SPSS软件进行分析。

同样的数据也在r中进行了分析。在这个片段中,检查了数据的同方差。
挑战
这个数据集的挑战很直接。学生将得到一份数据集简介和附有数据解释的代码本。简报中有学生需要回答的六个问题。这说起来容易做起来难:每个答案都是一个完整的30分钟的课程,解释如何运行t检验、方差分析、多元线性回归等等。
本课程教你如何在SPSS和r中运行这些分析,一旦你完成了练习,还有许多其他的挑战,你可以自己解决。
下载
不幸的是,这个数据集不是免费提供的。然而,通过注册人力资源统计学,你可以完全访问数据和学习材料。
结论
可用数据的缺乏是人力资源分析的瓶颈之一。我们希望通过本文部分地消除这个瓶颈。我们还为每个数据集提供了一些挑战,以确保您能最大限度地利用它。
缺点是这些数据集中只有两个包含真实数据。其余的都是人为产生的。这对于测试不同的技术仍然很有用。然而,创建这些数据可能是为了分享统计技术的实践或分享叙述。真实的数据没有同样的意图,因此更现实。
这可以通过从互联网上搜集真实数据来解决。Jared Valdron从这个开始,通过共享两个刮刀Meetup.com而且WeWork.这些可以作为灵感来生成您自己的数据集。
如果你知道我们遗漏的任何公开的人力资源分析数据,请在评论中告诉我们。我们将相应地更新这篇文章。

埃里克·范·沃彭
埃里克·范·沃彭是AIHR的创始人和院长。他是一位通过将技术创新引入人力资源环境来塑造现代人力资源实践的专家。他是全球公认的人力资源思想领袖,经常就人才分析、数字人力资源和工作的未来等主题发表演讲。
你准备好迎接HR的未来了吗?
在线学习现代和相关的人力资源技能
