使用R -聚类的人物分析教程

我们最近发表了一篇题为面向人力资源从业者的机器学习初学者指南,我们谈到了三种广泛的机器学习(ML)类型;强化、监督和无监督学习。在这篇后续文章中,我们将更深入地探讨无监督ML。我们将演示如何使用聚类分析(无监督ML的一个子集)智能地识别数据集中的相似性、模式和关系(就像人类一样——但更快或更准确),我们还包括了一些用r编写的实用代码示例,让我们开始吧!
人力资源中的聚类分析
我们要达到的目标是了解与员工流动率在我们的数据中。为此,我们基于一组员工变量(即特征),如年龄、婚姻状况、角色级别等,形成集群。集群帮助我们更好地理解可能与离职有关的许多属性,以及是否有不同的员工集群更容易受到离职的影响。这最后一个见解可以促进个性化的员工的经验通过确定当前的人力资源政策是否服务于分析中确定的员工集群,而不是使用一刀切的方法。
1.导入数据
我们首先导入分析所需的R库。我们在示例中使用的数据集是公开可用的——它是IBM Attrition数据集。你可以下载在这里如果你愿意跟我来。
suppressPackageStartupMessages({
图书馆(tidyverse)#数据主力
图书馆(readxl)#导入XLSX文件
图书馆(correlationfunnel)#快速探索性数据分析
图书馆(集群)#计算高空距离和PAM
图书馆(Rtsne)#降维和可视化
图书馆(图)#交互绘图
})
set.seed(175)#再现性
hr_data_tbl < -read_xlsx(“~ /桌面/ R /集群/数据/ datasets_1067_1925_WA_Fn-UseC_-HR-Employee-Attrition.xlsx”)
2.选择聚类变量
在正常情况下,我们会花时间探索数据——检查变量及其数据类型,可视化描述性分析(例如,单变量和双变量分析),理解分布,在需要时执行转换,以及处理缺失值和异常值。
然而,为了简单起见,我们将跳过这一步骤,而只是计算流失率与数据集中每个变量之间的相关性。相关性大于0.1的变量将被纳入分析。这有几个有用的原因,但最重要的是决定在我们的聚类分析中包含哪些变量。
相关(免费)资源!继续往下读↓
51人力资源指标备忘单
数据驱动的人力资源从实施相关的人力资源指标开始。下载51个人力资源指标的免费小抄
请记住,当涉及到集群时,包含更多变量并不总是意味着更好的结果。包含更多变量会使结果的解释复杂化,从而使最终用户难以根据结果采取行动。
检查数据集中减员与其他变量之间的关系强度
Hr_corr_tbl <- hr_data_tbl . Hr_corr_tbl% > %
选择(-EmployeeNumber)% > %
binarize(n_bin = 5, thresh_infreq = 0.01, name_infreq = "OTHER", one_hot = TRUE)% > %
关联(Attrition__Yes)
hr_corr_tbl% > %
plot_correlation_funnel()% > %
ggplotly()
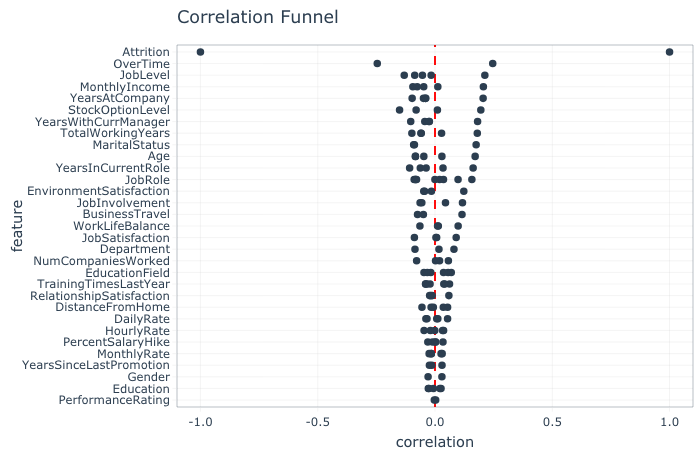
通过使用0.1的相关值作为临界值,分析建议包含14个变量进行聚类:从加班到商务旅行。在分析前的准备工作中,这14个字符数据类型的变量(例如MaritalStatus = Single)中的任何一个都被转换为因子数据类型(下文将详细介绍)。
#选择我们要分析的变量
var_selection < -c("EmployeeNumber", "减员","加班","JobLevel", "MonthlyIncome", " years in company ", "StockOptionLevel", "YearsWithCurrManager", " total work years ", "MaritalStatus", "Age", " yearsincurrent trole ", " job brole ", " environmental satisfaction ", "JobInvolvement", "BusinessTravel")
#几个变量是字符,需要转换为因子
Hr_subset_tbl <- hr_data_tbl% > %
选择(one_of(var_selection))% > %
mutate_if(是。character, as_factor)% > %
选择(EmployeeNumber、摩擦、一切())
3.分析:高尔距离
本质上,聚类都是关于确定数据集中的案例彼此之间有多相似(或不相似),以便我们可以将它们分组在一起。要做到这一点,我们首先需要根据所选的14个变量给每个案例(即员工)一个分数,然后根据这个分数确定员工之间的差异。
最常见的方法是计算“欧几里得距离”。然而,欧几里得距离仅适用于分析连续变量(例如,年龄,工资,任期),因此不适合我们的人力资源数据集,其中包括序数数据类型(例如,EnvironmentSatisfaction -值从1 =最差到5 =最好)和标称数据类型(MaritalStatus - 1 =单身,2 =离婚等)。因此,我们必须使用能够处理不同数据类型的距离度量;高尔距离。
高尔距离的主要优点是计算简单,理解直观。然而,这种方法的缺点是它需要一个距离矩阵,这是一种将数据集中的每个案例与其他案例进行比较的数据结构,对于大型数据集,这需要相当大的计算能力和内存。
#计算高尔距离并隐蔽到一个矩阵
gower_dist < -黛西(hr_subset_tbl [2:16], metric = "gower")
gower_mat < -as.matrix(gower_dist)
我们可以通过确定最相似和/或最不相似的员工对来对距离矩阵进行完整性检查。在这里,我们根据高尔距离得分计算出两个最相似的员工。
打印最相似的员工
hr_subset_tbl [哪一个(gower_mat= =最小值(gower_mat [gower_mat! =最小值(gower_mat)]),加勒比海盗。ind = TRUE)[1,],]## #小猫咪:2 x 16
##员工流失率加班工作级别月收入在公司
##
## 1 1624是是1 1569 0
## 2 614是是1 1878 0
## #…与10个变量:StockOptionLevel
## #总工作年限
## # YearsInCurrentRole
## # JobInvolvement
我们从健康检查中了解到,EmployeeID 1624和EmployeeID 614(我们称它们为Bob和Fred)被认为是相似的,因为除了月薪外,它们对15个变量中的每个变量都显示相同的值。两人都离开了公司,曾经在初级职位上加班,薪水也差不多。高尔度量似乎是有效的,输出是有意义的,现在让我们进行聚类分析,看看我们是否能够理解人员流动率。
4.分析:有多少簇?
执行聚类分析时必须回答的一个大问题是“我们应该将数据集划分为多少个聚类?”
我们可以使用数据驱动的方法通过计算轮廓宽度来确定最佳的簇数。有了这个指标,我们可以衡量每个观察结果(例如,在我们的例子中是一名员工)与它所分配的集群的相似程度,以及与相邻集群的不同程度。度量的范围从-1到1,其中值1表示清晰的集群分配,0表示弱集群分配(即,一个案例可能被分配给两个相邻集群中的一个),而-1表示错误的集群分配。
#确定数据的最佳簇数
sil_width < -map_dbl(2:10,函数(k) {
模型< -帕姆(gower_dist, k = k)
模型$silinfo$avg.width
})
sil_tbl < -宠物猫(
K = 2:10,
Sil_width = Sil_width
)
#打印(sil_tbl)
图< -ggplot(sil_tblaes(x = k, y = sil_width))+
geom_point(size = 2)+
geom_line()+
scale_x_continuous(断点= 2:10)
ggplotly(图)
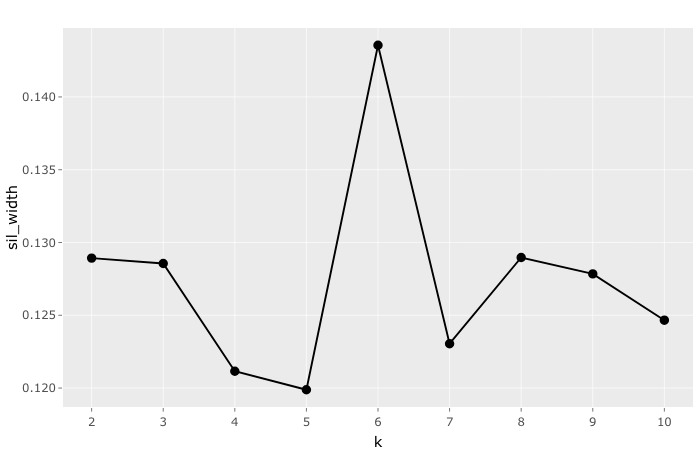
为了识别具有最高轮廓宽度的聚类数量,我们使用不同数量的聚类进行聚类分析。在我们的例子中,我们选择了2到10个集群。我们将集群的最大数量限制在10个的原因是,数字越大,解释和最终采取行动的难度就越大。从图中可以看出,六个簇产生了最高的平均轮廓宽度,因此将用于我们的分析。
需要注意的是,平均轮廓值(0.14)实际上相当低。根据坊间证据,理想情况下,我们希望最小值介于0.25和0.5之间考夫曼和卢梭,1990).我们的低值可能表明数据结构有限,或者表现较弱的集群比其他集群(即,一些集群松散地分组,而另一些集群紧密地分组)。为了找出低值背后的更多原因,我们选择了观察集群产生的实际见解,并使用t-分布式随机邻居嵌入(t-SNE)可视化集群结构。下面将解释这两种方法。
5.分析:解释集群
尽管已经进行了聚类,但我们还没有讨论的主题是所采用的聚类分析方法。
在这个分析中,我们使用了围绕中间体的分区(PAM)方法。这种方法与K-Means是最常见的聚类形式。唯一的区别是PAM的聚类中心是由原始数据集观测值定义的,在我们的示例中,原始数据集观测值是我们的14个变量。与K-Means聚类相比,这种PAM方法有两个主要优点。首先,它对异常值(例如,非常高的月收入)不太敏感。其次,PAM还为每个聚类提供了一个范例案例,称为“Medoid”,这使得聚类解释更加容易。
考虑到这一点,让我们用6个聚类重新运行聚类分析,根据我们的平均轮廓宽度,将聚类分析结果与原始数据集连接起来,以确定每个个体属于哪个聚类,然后仔细观察代表我们的6个聚类的6个medoid。
K <- 6
pam_fit < -帕姆(gower_dist, diss = TRUE, k)
Hr_subset_tbl <- Hr_subset_tbl . Hr_subset_tbl% > %
变异(cluster = pam_fit .$集群)
#看一下质心来了解星团
hr_subset_tbl [pam_fit$medoids,)
## #小猫咪:6 x 17
##员工流失率加班工作级别月收入在公司
##
## 1 1171 No No 2 5155
## 2 35 No No 2 6825 9
## 3 65是是是1 3441 2
## 4 No No 1 2713
## 5 747 No No 2 5304
## 6 1408 No No 4 16799 20
## #…11个变量:StockOptionLevel
## #总工作年限
## # YearsInCurrentRole
## # JobInvolvement
为了更好地理解我们人口中的流失率,我们计算了每个聚类中的流失率,以及每个聚类在我们的数据集中捕获了多少整体流失率。
Attrition_rate_tbl <- hr_subset_tbl . Attrition_rate_tbl% > %
选择(集群,摩擦)% > %
变异(attrition_num = (as.numeric(摩擦)* - - - - - -1)+2)% > %
group_by(集群)% > %
总结(
Cluster_Turnover_Rate = (总和(attrition_num)/长度(attrition_num))% > %尺度::百分比(准确度= 0.1),
Turnover_Count =总和(attrition_num),
Cluster_Size =长度(attrition_num)
)% > %
取消组()% > %
变异(Population_Turnover_Rate =/总和(Turnover_Count))% > %尺度::百分比(准确度= 0.1))
##“summary()”取消输出分组(用“。组的参数)
attrition_rate_tbl
## #小猫咪:6 x 5
cluster_turnover_count Cluster_Size Population_Turnover_…
##
1 1 8.6% 23 268 9.7%
2 2 8.6% 24 280 10.1%
3 3 79.7% 141 177 59.5%
## 4 4 8.0% 29 364 12.2%
## 5 5 4.0% 8 202 3.4%
6 6 6.7% 12 179 5.1%
现在很明显,集群3中近80%的员工离开了组织,这约占整个数据集中记录的所有人员流动率的60%。太棒了!我们所确定的集群似乎产生了一些与人员流动率明显相关的分组。基于此,我们可以收集一个描述性的理解与周转率相关的变量的组合。
不幸的是,到目前为止,我们基于代码的输出更适合数据分析师,而不是业务合作伙伴和人力资源利益相关者。为了使结果对非分析人员更容易理解和操作,我们将它们可视化。
将聚类分析中的许多变量一起可视化的一种方法是使用称为t-SNE的方法。这种方法是一种降维技术,旨在保留数据的结构,同时将其降至二维或三维——这是我们可以可视化的!从技术上讲,这一步骤是不必要的,但建议这样做,因为它有助于促进对结果的理解,从而增加利益相关者采取行动的可能性。此外,它使我们能够检查集群结构,这被我们的平均轮廓宽度度量确定为弱。
我们首先为可视化创建标签,执行t-SNE计算,然后可视化t-SNE输出。
Data_formatted_tbl <- hr_subset_tbl% > %
left_join(attrition_rate_tbl)% > %
重命名(Cluster = Cluster)% > %
变异月收入=月收入% > %尺度::美元())% > %
变异(描述=str_glue(“人员流失率={减员}
MaritalDesc = {MaritalStatus}
年龄:
JobRole = {JobRole}
工作级别{JobLevel}
加班={加班}
当前角色任期= {YearsInCurrentRole}
专业任期={总工作年限}
月收入={月收入}
集群的集群:{}
集群大小:{Cluster_Size}
集群流动率:{Cluster_Turnover_Rate}
集群周转计数:{Turnover_Count}
"))
##连接,by = "cluster"
#使用t-SNE在二维空间中映射集群
tsne_obj < -Rtsne(gower_dist, is_distance = TRUE)
Tsne_tbl <- tsne_obj . txt$Y% > %
as_tibble()% > %
setNames(c(" X "、" Y "))% > %
bind_col(data_formatted_tbl)% > %
变异(Cluster = Cluster% > %as_factor())
G <- tsne_tbl% > %
ggplot(aes(x = x, y = y, color = Cluster))+
geom_point(aes(text = description))
##警告:忽略未知的美学:文本
ggplotly(g)
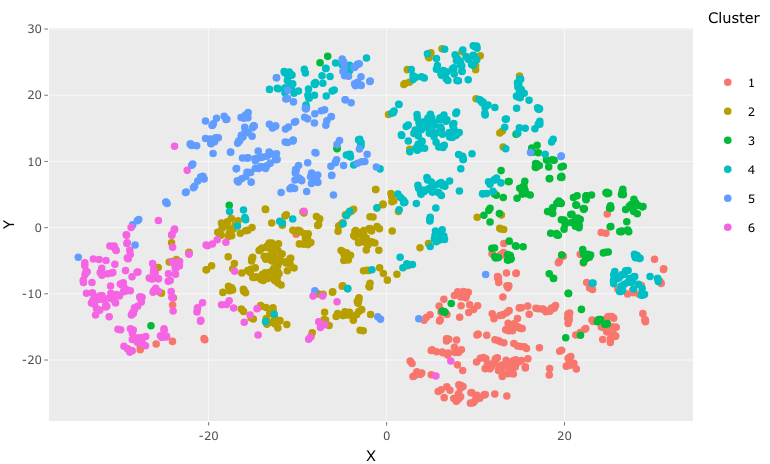
绘图允许我们在两个维度上绘制聚类分析结果,使最终用户能够可视化以前的代码和概念。
正如前面的平均轮廓宽度度量(0.14)所示,集群的分组是“可使用的”。每个集群中都有一些案例与集群中的其他案例相距较远,但通常,集群似乎在某种程度上聚集在一起(集群4表现最弱)。从实际的角度来看,让人放心的是,集群3捕获的80%的案例都与员工离职有关,从而使我们能够更好地了解这一人群中的人员流失。
以html格式浏览图表时(去这里要在html中查看它们),我们可以将鼠标悬停在可视化中的任何点上,并找出它的集群成员、集群流动率指标以及与该员工相关的变量值。当我们在集群3中的案例上徘徊时,我们看到与员工相关的变量与我们的集群3中的Medoid类似,更年轻,科学和销售专业人员,具有几年的专业经验,在公司的任期最短,并且离开了公司。我们开始建立一个与人员流动相关的“角色”,这意味着人员流动不再是一个概念问题,它现在是一个我们可以描述和理解的人。
理想情况下,这些知识使我们能够制定量身定制的干预措施和策略,以改善组织内的员工体验,并减少不必要的人员流动风险。我们从进行聚类分析中获得的最大好处是,干预策略适用于一个相当大的群体;整个集群,从而使其更具成本效益和影响力。
此外,分析还向我们展示了员工流失率不是问题的领域。在审查我们的员工产品(例如,政策和实践)以及这些产品如何解决我们六个集群/角色的人员流动时,这些信息也可能是有价值的。此外,它还可以影响我们在未来员工体验计划和员工战略上的投资方式。
最后一点
在这个实例中,我们演示了使用混合数据类型来执行聚类分析(无监督ML)的过程,以理解人力资源数据集中的人员流动主题。聚类分析虽然不是解决所有人力资源问题的灵丹妙药,但却是一种理解人力资源领域的主题和人员的强大方法,它可以为人力资源从业者实用地扩展个性化员工体验的方式提供信息,并摆脱一刀切的方法。


亚当·麦金农
亚当他是澳大利亚墨尔本Reece集团的人员数据与分析主管。亚当拥有心理学、信息技术、流行病学和金融学等多学科的学术背景,他提倡在工作中提出两个问题:那又怎样?和2。现在怎么办呢?他负责通过统计和机器学习综合与人相关的主题的规模,使组织能够在决策中以员工为中心。
你准备好迎接HR的未来了吗?
在线学习现代和相关的人力资源技能