使用R的人员分析教程-员工流失

这是AIHR Analytics上发布的关于员工流失的三篇系列文章中的最后一篇。在这篇文章中,我将演示如何建立、评估和部署你的预测离职模型,使用R。
首先,我将简要介绍我对员工流失的看法,并总结数据科学过程。
你可能会问什么是员工流失?总之,离职,就是员工离开公司。换句话说,终止,无论是自愿的还是非自愿的。从最广泛的意义上讲,人员流失率既涉及人们离开组织的比率,也涉及个人自我终止的比率。
过去的焦点大多集中在“费率”上,而不是单个的终止。我们计算过去的利率或营业额为了尝试预测未来的人员流动率.这样做并继续这样做确实很重要。在这方面,数据仓库工具非常强大,可以在不同的时间段、不同的粒度级别上高效地分割数据。但这只是事情的一半。
这些人员流动率只显示了“总体”的流失或人员流动率的影响。除此之外,你可能会对预测“谁”或“哪些员工”可能有很高的离职风险感兴趣。这就是为什么我们除了对整体感兴趣外,还对个人感兴趣。
从统计学上讲,不管上下文如何,“流失”就是“流失”。它是指一个群体中的一个成员离开了一个群体。你会在微软AzureML和许多数据科学教科书中看到的一个例子是“客户”流失。这是市场营销的背景。
相关(免费)资源!继续往下读↓
51人力资源指标备忘单
数据驱动的人力资源从实施相关的人力资源指标开始。下载51个人力资源指标的免费小抄
在手机公司等许多企业中,产生和吸引新客户远比留住老客户难。因此,企业希望尽其所能留住现有客户。当他们离开时,这就是该特定公司的“客户流失”。
这种思维和心态同样适用于人力资源部门。一旦你拥有了好员工,“留住”他们的成本远低于吸引和培训新员工的成本。因此,我们有一个适用于人力资源管理的营销原则,以及一套数据科学算法,可以帮助确定我们的数据中是否存在流失模式,从而帮助预测未来的流失。
这个分析是一个例子,说明人力资源需要开始跳出传统的思维模式。这一分析有助于解决未来人力资源的挑战和问题。
在个人层面上,我喜欢将人员分析视为将数据科学过程应用于人力资源信息。出于这个原因,我愿意重新审视这个过程是什么,并使用它作为框架来指导本文示例的其余部分。
重新审视数据科学过程
数据科学过程包括六个步骤。
- 确定一个目标。如上所述,这意味着确定人力资源管理
你正试图解决的业务问题。没有问题或问题要解决,我们就没有
的目标。 - 收集和管理数据。简单地说,你需要一个与问题相关的信息“数据集”。数据的收集和管理可以是公司人力资源信息系统的简单提取,也可以是精心设计的数据仓库的输出商业智能用于HR信息的工具。出于本文的目的,我们将使用一个简单的字符分隔值(CSV)文件。它还包括对数据质量问题的研究,以及对数据可能告诉您的信息的初步了解
- 构建模型。在定义了人力资源业务问题或试图实现的目标之后,您可以选择一种旨在解决这类问题的数据挖掘方法或工具。通过员工流失,你可以预测哪些人会离开,哪些人会留下。业务问题决定了要考虑的适当数据挖掘工具。建模中常用的数据挖掘方法有分类、回归、异常检测、时间序列、聚类和关联分析等。这些方法将信息/数据作为输入,通过统计算法运行它们,并产生输出。
- 评价和批判模型。每种数据挖掘方法都可以使用许多不同的统计算法来处理数据。评估既包括哪些算法对新数据提供了最一致准确的预测,也包括我们是否拥有所有相关数据——或者我们是否需要更多类型的数据来提高模型的预测精度?随着时间的推移,这个过程可以是一个重复的循环活动,以改进模型
- 展示结果和文件。当我们的模型达到可接受的、有用的预测水平时,我们记录我们的活动并呈现结果。可接受和有用的定义实际上是与组织相关的,但在所有情况下都意味着结果显示出比其他情况下的改进。与任何科学一样,数据“科学”背后的原则是,使用相同的数据和方法,人们应该能够重现我们的发现。
- 部署模型。建立模型(基于现有数据)的全部目的是:
- 在未来数据可用时使用该模型来预测或防止某事发生
- 为了更好地了解我们现有的业务问题,以制定更具体的应对措施
步骤1。明确目标
我们假设的公司想要应用数据科学原理和步骤来处理一个关键的人力资源问题:员工流失。它意识到,当优秀人才离开时,填补他们的成本远远高于为他们提供留住他们的激励措施。因此,它希望在关于员工留任的人力资源决策中受到数据的驱动。

以下是他们希望回答的问题:
- 我们离职的员工比例是多少?
- 它发生在哪里?
- 年龄和服务年限如何影响终止?
- 还有什么,如果有的话?
- 我们能预测未来的终止吗?
- 如果是的话,我们能预测得多好呢?
步骤2—数据收集和管理
通常,用于分析问题的数据都是从当前可用的数据开始的。在对预测模型进行一些初始原型化之后,会出现收集额外数据以进一步完善模型的想法。因为这是第一次尝试,所以组织只使用现成的东西。
在与他们的人力资源信息系统工作人员咨询后,他们发现他们可以获得以下信息:
- EmployeeID
- 记录日期
- 出生日期
- 原租用日期
- 终止日期(如终止)
- 年龄
- 服务年限
- 城市
- 部门
- 职称
- 商店的名字
- 性别
- 终止原因
- 终止类型(自愿或非自愿)
- Status年数据年份
- 状态-在状态年期间激活或终止
- 业务部门-商店或总部
该公司发现,从2006年到2015年,他们有10年的良好数据。它想用2006-2014年作为训练数据,用2015年作为测试数据。数据包括
- 所有活跃员工在每年年底的快照结合
- 每一年发生的终止。
因此,每年都会有状态为“活动”或“终止”的记录。在上面列出的信息项中,“STATUS”项是“因变量”。这是需要预测的类别。其他的都是自变量。他们是潜在的预测者。
首先看数据——结构
让我们加载数据。(顺便说一下,下面的数据完全是不自然的)
你可以找到这家公司的数据集在这里.请随意在本教程中使用这些数据集。
加载一个R数据帧。MFG10YearTerminationData < -read.csv(~/Visual Studio 2015/Projects/EmployeeChurn/EmployeeChurn/MFG10YearTerminationData.csv) MYdataset <- MFG10YearTerminationDatastr(MYdataset) ## 'data.frame': 49653 obs。## $ EmployeeID: int 1318 1318 1318 1318 1318 1318 1318 1318 1318 1318 1318 1318 1318 1318 1318 1318 1318 1318 1318 1318 1318…## $ recorddate_key:因子w/ 130级别“1/1/2006 0:00”,..: 41 42 43 44 45 46 47 48 49 50…## $ birthdate_key:因子w/ 5342级别“1941-01-15”,“1941-02-14”,..: 1075 1075 1075 1075 1075 1075 1075…## $ orighiredate_key:因子w/ 4415级别"1989-08-28","1989-08-31",..: 1 1 1 1 1 1 1 1 1 1 1…## $ terminationdate_key:因子w/ 1055级别“1900-01-01”,“2006-01-01”,..: 1 1 1 1 1 1 1 1 1 1 1…## $年龄:int 52 53 54 55 56 57 58 59 60 61…## $ length_of_service: int 17 18 19 20 21 22 23 24 25 26…## $ city_name:因子w/ 40级别“Abbotsford”,“Aldergrove”,..: 35 35 35 35 35 35 35 35 35 35 35 35…## $ department_name:因素w/ 21级“会计”,“应付账款”,..: 10 10 10 10 10 10 10 10 10 10… ## $ job_title : Factor w/ 47 levels "Accounting Clerk",..: 9 9 9 9 9 9 9 9 9 9 ... ## $ store_name : int 35 35 35 35 35 35 35 35 35 35 ... ## $ gender_short : Factor w/ 2 levels "F","M": 2 2 2 2 2 2 2 2 2 2 ... ## $ gender_full : Factor w/ 2 levels "Female","Male": 2 2 2 2 2 2 2 2 2 2 ... ## $ termreason_desc : Factor w/ 4 levels "Layoff","Not Applicable",..: 2 2 2 2 2 2 2 2 2 2 ... ## $ termtype_desc : Factor w/ 3 levels "Involuntary",..: 2 2 2 2 2 2 2 2 2 2 ... ## $ STATUS_YEAR : int 2006 2007 2008 2009 2010 2011 2012 2013 2014 2015 ... ## $ STATUS : Factor w/ 2 levels "ACTIVE","TERMINATED": 1 1 1 1 1 1 1 1 1 1 ... ## $ BUSINESS_UNIT : Factor w/ 2 levels "HEADOFFICE","STORES": 1 1 1 1 1 1 1 1 1 1 ...图书馆(plyr)图书馆(dplyr) ## ##附加包:'dplyr' ## ## 'package:plyr': ## ## arrange, count, desc, failwith, id, mutat, rename, summarise, ## summary ## ## 'package:stats'中屏蔽了以下对象:## ## filter, lag ## ## 'package:base'中屏蔽了以下对象:## ## intersect, setdiff, setequal, union
再看数据-数据质量
现在,我们将使用一些简单的描述性统计数据(包括最小值、平均值和最大值)来评估数据质量,并创建一些计数。

总结(MYdataset) ## EmployeeID recorddate_key birthdate_key ##最小值:1318 12/31/2013 0:00:5215 1954-08-04:40 ##第一个数据区:3360 12/31/2012 0:00:5101 1956-04-27:40 ##中值:5031 12/31/2011 0:00:4972 1973-03-23:40 ##平均值:4859 12/31/2014 0:00:4962 1952-01-27:30 ##第三个数据区:6335 12/31/2010 0:00:4840 1952-08-10:30 ##最大。:8336 12/31/2015 0:00: 4799 1953-10-06: 30 ## (Other):19764 (Other):49443 ## orighiredate_key terminationdate_key age length_of_service ## 1992-08-09: 50 1900-01-01:42450 Min.:19.00 Min.: 0.00 ## 1995-02-22: 50 2014-12-30: 1079 1st Qu.:31.00 1st Qu.: 5.00 ## 2004-12-04: 50 2015-12-30: 674中位数:42.00中位数:10.00 ## 2005-10-16:50 2010-12-30:25平均:42.08平均:10.43 ## 2006-02-26:50 2012-11-11:21第三Qu.:53.00第三Qu.:15.00 ## 2006-09-25: 50 2015-02-04: 20最大: 65.00马克斯。:26.00 ##(其他):49353(其他):5384 ## city_name department_name job_title ##温哥华:11211肉类:10269切肉机:9984 ##维多利亚:4885乳制品:8599乳品人:8590 ##纳奈莫:3876农产品:8515农产品店员:8237 ##新威斯敏斯特:3211面包店:8381面包师:8096 ##基洛纳:2513客服:7122收银员:6816 ##伯纳比:2067加工食品:5911货架Stocker:5622 ##(其他):21890(其他):856(其他):2308 ## store_name性别_short性别_full termreason_desc ##最小值:1.0 F:25898女:25898裁员:1705 ##第一曲:16.0 M:23755男:23755不适用:41853 ##中位数:28.0辞职:2111 ##平均:27.3退休:3984 ##第三曲:42.0 ##最大。:46.0 ## ## termtype_desc STATUS_YEAR STATUS ##非自愿:1705最小值:2006活跃:48168 ##不适用:41853第1季:2008终止:1485 ##自愿:6095中位数:2011 ##平均:2011 ##第3季:2013 ##最大:2015 ## ## business_unit总部:585门店:49068 ## ## ## ## ##
粗略地看一下上面的摘要,并没有发现任何数据质量问题。
相关:概述人力资源指标
第三次看数据——一般来说,数据告诉我们什么?
之前我们已经指出,从2006年到2015年的10年里,我们每年都有年末的活动记录和年内的终止记录。为了有一个用于建模的总体(以区分active和TERMINATES),我们必须包括这两种状态类型。
然后,获得终止在整个总体中的百分比/比例的基线是有用的。这也回答了我们的第一个问题。让我们看下一个。
我们离职的员工比例是多少?
StatusCount < -as.data.frame.matrix(MYdataset % > %group_by(STATUS_YEAR) % > %选择(地位)% > %表格StatusCount$TOTAL<-StatusCount$ACTIVE + StatusCount$TERMINATED StatusCount$PercentTerminated <-StatusCount$TERMINATED/(StatusCount$TOTAL)*One hundred.StatusCount ## ACTIVE TERMINATED TOTAL PercentTerminated ## 2006 4445 134 4579 2.926403 ## 2007 4521 162 4683 3.459321 ## 2008 4603 164 4767 3.440319 ## # 2009 4710 142 4863 2.478340 ## 2011 4972 110 5082 2.164502 ## 2012 5101 130 5231 2.485184 ## 2013 5215 105 5320 1.973684 ## 2014 4962 253 5215 4.851390 ## 2015 4799 162 4961 3.265471的意思是(StatusCount$PercentTerminated) ## [1] 2.997124
看起来在1.97 - 4.85%之间,平均为2.99%
终止发生在哪里?
让我们看一些图表
按业务单位划分
图书馆(ggplot2)ggplot() +geom_bar(aes(y =. . . .,x =as.factor(BUSINESS_UNIT),填补=as.factor(地位)),data =MYdataset,位置=position_stack())
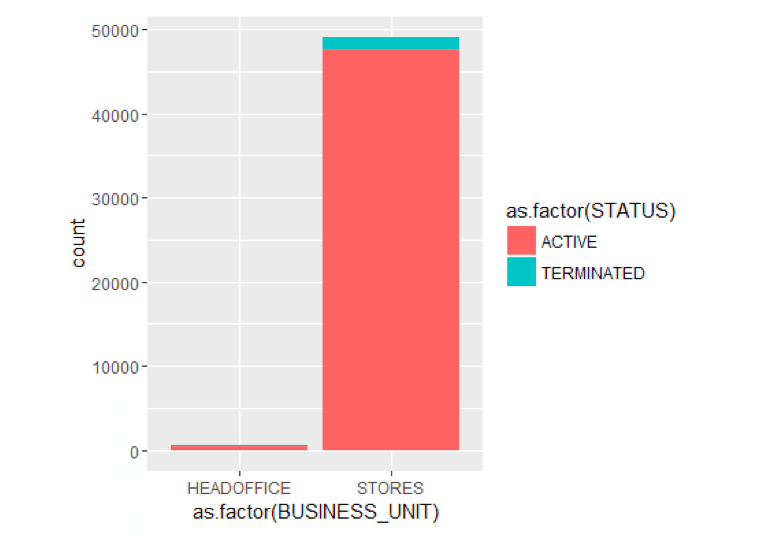
看起来,在过去的10年里,终止主要发生在STORES业务部门。只有一个在总部的人力资源技术部。
让我们花点时间研究一下这些终止。
按终止类型和状态年终止
TerminatesData < -as.data.frame(MYdataset % > %过滤器(状态= =“终止”))ggplot() +geom_bar(aes(y =. . . .,x =as.factor(STATUS_YEAR),填补=as.factor(termtype_desc))、数据= TerminatesData位置=position_stack())
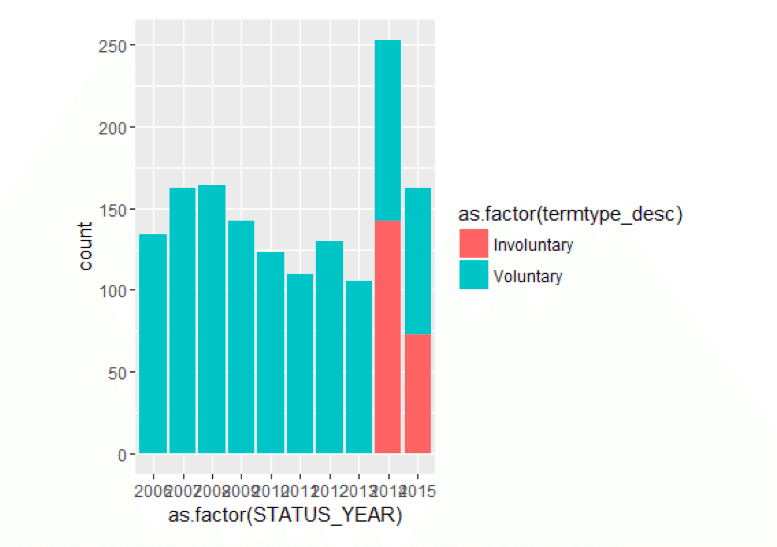
一般来说,每年大多数的终止似乎都是自愿的,除了近年来出现了一些非自愿的终止。顺便说一下,这些见解通常包含在劳动力仪表板.
按状态年份和终止原因终止
ggplot() +geom_bar(aes(y =. . . .,x =as.factor(STATUS_YEAR),填补=as.factor(termreason_desc))、数据= TerminatesData位置=position_stack())
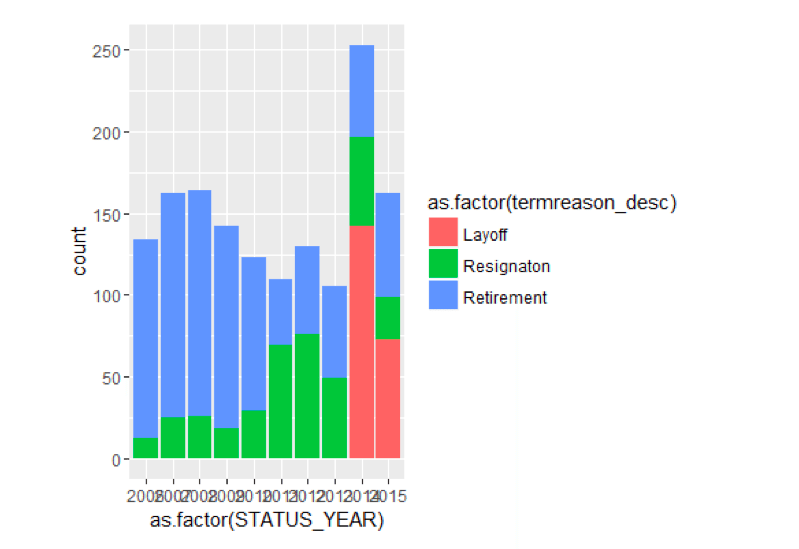
似乎2014年和2015年有裁员,导致了非自愿解雇。
按终止原因和部门终止
ggplot() +geom_bar(aes(y =. . . .,x =as.factor(department_name),填补=as.factor(termreason_desc))、数据= TerminatesData位置=position_stack()) +主题(axis.text.x =element_text(角=90hjust =1vjust =0.5))
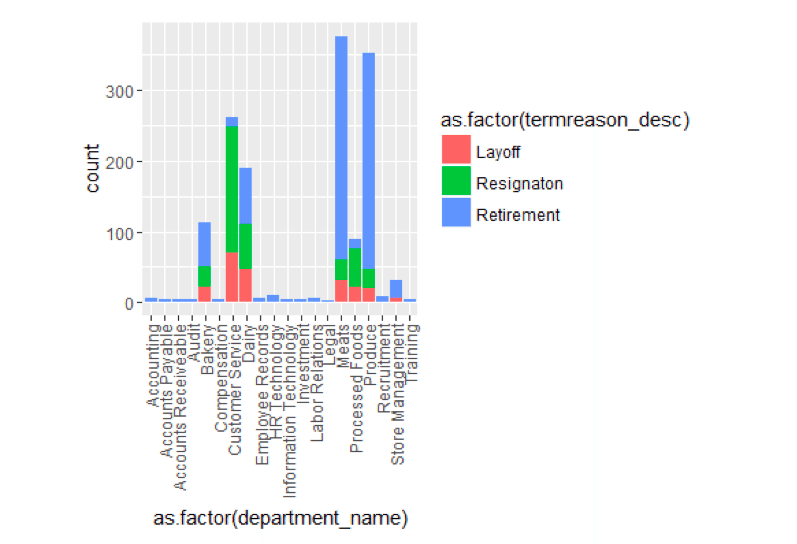
当我们按部门查看终止时,有一些东西突出来了。与其他部门相比,客服部门的离职比例要大得多。总的来说,很多部门的退休人数都很高。
年龄和服务年限如何影响终止?
图书馆(插入)##加载所需的包:格子featurePlot(x =MYdataset (,6:7),y =MYdataset美元地位,情节=“密度”,汽车。关键=列表(列=2))
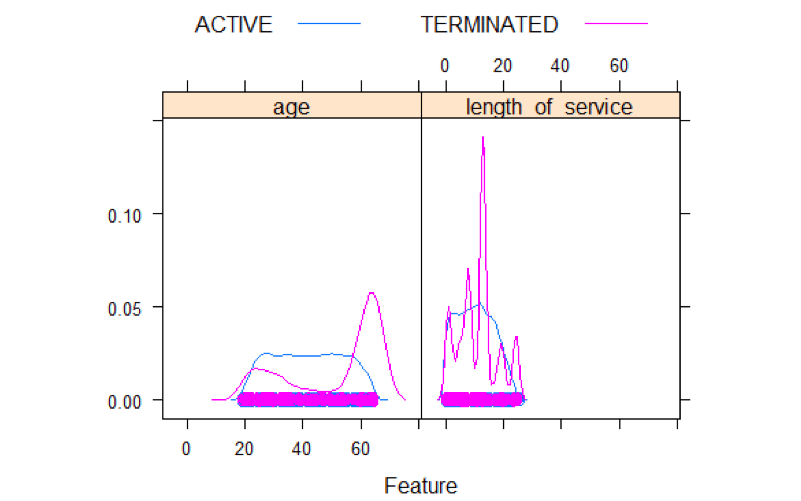
密度图显示了一些有趣的东西。对于终止,有一些从20到30的上升和60的峰值。服务年限有5个峰值。一个大约1年,另一个大约5年,一个大的大约15年,还有几个20年和25年。
年龄和服务年限按状态分配
featurePlot(x =MYdataset (,6:7),y =MYdataset美元地位,情节=“盒子”,汽车。关键=列表(列=2))
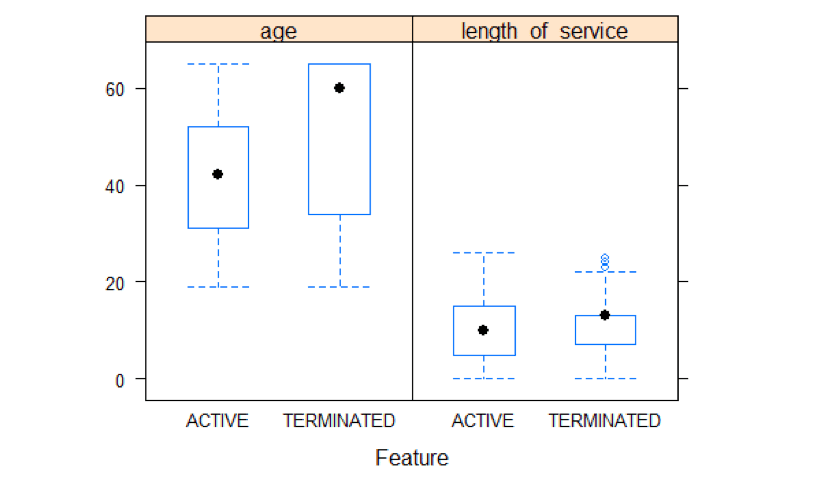
箱线图分析显示,与活跃用户相比,终止用户的平均年龄较高。在职员工与终止员工的服务年限差异不大。
这是对数据所告诉我们的一些事情的简要概括。我们的下一步是建立模型。
相关:键的概述员工绩效指标
步骤3 -建立模型
应该再次提到的是,对于构建模型,我们从来不想使用所有我们的数据来建立模型。这可能会导致过拟合,在这种情况下,它可能能够很好地预测它认为是基于当前数据的,但可能无法很好地预测它没有见过的数据。
我们有10年的历史数据。这是很多,通常情况下,公司只与几年的工作。在我们的例子中,我们将使用前9年来训练模型,并使用第10年来测试它。此外,我们还将在训练数据上使用10倍交叉验证。所以在我们真正尝试各种建模算法之前,我们需要将数据划分为训练数据集和测试数据集。
让我们划分数据
图书馆(拨浪鼓)##拨浪鼓:一个免费的图形界面的数据挖掘与R. ## 4.0.5版本版权所有(c) 2006-2015 Togaware Pty Ltd. ##输入'拨浪鼓()'摇晃,拨浪鼓,并滚动您的数据。图书馆(magrittr)对于%>%和%<>%操作符。建筑真实评分#一个预定义的值用来重置随机种子,这样结果是可重复的。crv种子42美元加载一个R数据帧。MFG10YearTerminationDataread.csv(~/Visual Studio 2015/Projects/EmployeeChurn/EmployeeChurn/MFG10YearTerminationData.csv) MYdataset#创建训练和测试数据集set.seed(crv种子美元)MYnobsnrow(MYdataset)# 52692观察结果MYsample的子集(MYdataset,STATUS_YEAR<=2014子集(MYdataset STATUS_YEAR = = 2015)下面的变量选择已经被注意到。MYinputc("age", "length_of_service", "gender_full", "STATUS_YEAR", "BUSINESS_UNIT") MYnumericc("age" "length_of_service" "STATUS_YEAR") MYcategoricc(“gender_full”、“BUSINESS_UNIT”) MYtarget“STATUS”MYrisk NULL MYident“EmployeeID”MYignorec("recorddate_key", "birthdate_key", "orighiredate_key", "terminationdate_key", "city_name", "gender_short", "termreason_desc", "termtype_desc","department_name","job_title", "store_name"MYTrainingData<-MYtrain[c(MYinput, MYtarget)] MYTestingData<-MYtest[c(MYinput MYtarget))
模型的选择和运行
R的特点之一是,它可以使用的函数和过程的数量是巨大的。所以通常有很多种做事的方法。为数据科学设计的两个最佳R包是脱字符号而且喋喋不休的人.
我们在上一篇博客文章中介绍了插入符号。必威 官方网站在这个例子中,我会用喋喋不休的人.值得一提的是,它提供了一个GUI前端,并在后端的日志中为其生成代码。所以你可以快速生成模型。
在本文中,我不会演示如何将rattle作为GUI使用,而是展示它生成的代码以及统计结果和图表。请不要为所呈现的代码而挂机/关机。GUI前端生成了下面所有的代码。我只是做了一些表面上的改变。请务必将本文中的数据科学流程作为如何实现的示例。作为一个GUI, rattle能够在我大约15分钟的时间内生成以下所有输出。可以找到一个关于Rattle GUI的教程在这里.和这里有一本书喋喋不休的人。
我们应该先退一步回顾一下我们在做什么,我们的开场问题是什么。我们想要预测谁会在未来终止妊娠。这是一个“二元结果”或“类别”。一个人要么是“活跃的”,要么是“终止的”。由于这是一个要预测的类别,我们将在可以预测类别的模型/算法中进行选择。
我们将在rattle中看到的模型是:
- 决策树(rpart)
- 增强模型(adaboost)
- 随机森林(rf)
- 支持因子模型(svm)
- 线性模型
决策树
首先让我们看一下决策树模型。这总是很有用的,因为有了这些,你可以得到一个可视化的树模型,以一种容易理解的方式了解预测是如何发生的。
图书馆(使)图书馆(rpart静静地=真正的)#重置随机数种子以每次获得相同的结果。set.seed(crv种子美元)#建立决策树模型。MYrpartrpart(状态~,data =MYtrain (,c(MYinput MYtarget)),方法=“类”,改=列表(分=“信息”),控制=rpart.control(usesurrogate =0maxsurrogate =0))生成决策树模型的文本视图。#打印(MYrpart) # printcp (MYrpart) #猫(“\ n”)#时间:0.63秒 #============================================================ # 摇铃时间戳:2016-03-25 09:45:25 x86_64-w64-mingw32 #情节产生的决策树。#我们使用rpart。策划方案。fancyRpartPlot(MYrpart主要=“决策树MFG10YearTerminationData $ STATUS”)
我们现在可以回答上面的问题了
还有什么,如果有的话?
甚至从图形树输出来看,性别和地位年份也会影响它。
随机森林
现在来看随机森林
#============================================================ # 摇铃时间戳:2016-03-25 18:21:29 x86_64-w64-mingw32 #随机森林#“randomForest”包提供了“randomForest”功能。图书馆(randomForest静静地=真正的##输入rfNews()查看新功能/更改/错误修复。## ##加载包:'randomForest' ## ##下面的对象从'package:ggplot2'中屏蔽:## ## margin ## ##下面的对象从'package:dplyr'中屏蔽:## ## combine#建立随机森林模型。set.seed(crv种子美元)MYrfrandomForest(状态~,data =MYtrain [c (MYinput MYtarget)],ntree =500mtry =2,重要性=真正的,na.action= randomForest:: na.roughfix,取代= FALSE)生成“随机森林”模型的文本输出MYrf ## ##调用:## randomForest(公式= STATUS ~ ., data = MYtrain[c(我的输入,我的目标)],ntree = 500, mtry = 2,重要性= TRUE,替换= FALSE, na。action = randomForest::na.roughfix) ##随机森林类型:分类##树木数量:500 #### ## OOB估计错误率:1.13% ##混淆矩阵:## ACTIVE终止类。错误## ACTIVE 43366 3 6.917383e-05 ##已终止501 822 3.786848e-01“pROC”包实现各种AUC功能。计算曲线下面积(AUC)。pROC::中华民国(MYrf $ y,as.numeric(MYrf$预测))## ##调用:## roc.default(response = MYrf$y, predictor = as.numeric(MYrf$预测))## ##数据:as.numeric(MYrf$ y预测)在43369控制(MYrf$y ACTIVE) < 1323例(MYrf$y TERMINATED)。曲线下面积:0.8106#计算AUC置信区间。pROC::ci.auc(MYrf $ y,as.numeric95%可信区间:0.7975-0.8237(德隆)列出变量的重要性。rn轮(randomForest::重要性(MYrf),2rn) (订单(rn,3.),减少=真正的), ## ACTIVE TERMINATED MeanDecreaseAccuracy meandecreaschinini ##年龄36.51 139.70 52.45 743.27 ## STATUS_YEAR 35.46 34.13 41.50 64.65 ## gender_full 28.02 40.03 37.08 76.80 ## length_of_service 18.37 18.43 21.38 91.71 ## BUSINESS_UNIT 6.06 7.64 8.09 3.58#耗时:18.66秒
演算法
现在来看Adaboost
#============================================================ # 摇铃时间戳:2016-03-25 18:22:22 x86_64-w64-mingw32 # Ada促进#的Ada包实现了提升算法。#构建Ada Boost模型。set.seed(crv种子美元)MYada艾达(状态~,data =MYtrain [c (MYinput MYtarget)],控制=rpart:: rpart.control (maxdepth =30.cp =0.010000minsplit =20.xval =10), iter =50)#打印建模结果。打印(MYada) ##调用:## ada(STATUS ~ ., data = MYtrain[c(MYinput, MYtarget)], control = rpart::rpart.)control(maxdepth = 30, ## cp = 0.01, minsplit = 20, xval = 10), iter = 50) ## ## Loss: exponential Method: discrete Iteration: 50 ## ## Final Confusion Matrix for Data: ## Final Prediction ## True value ACTIVE TERMINATED ## ACTIVE 43366 3 ## TERMINATED 501 822 ## ## Train Error: 0.011 ## ## Out-Of-Bag Error: 0.011 iteration= 6 ## ## Additional Estimates of number of iterations: ## ## train.err1 train.kap1 ## 1 1轮(MYada模型错美元[MYada iter美元],2)火车。做错火车。Kap ## 0.01 0.24猫('树结构中实际使用的变量:\n'##树结构中实际使用的变量:打印(排序(名称(listAdaVarsUsed(MYada)))) # #[1]“年龄”“gender_full”“length_of_service”# #[4]“STATUS_YEAR”猫(实际使用变量的频率:\n') ## ##实际使用变量的频率:print (listAdaVarsUsed(MYada)) ## ## age STATUS_YEAR length_of_service gender_full ## 43 41 34 29
支持向量机
现在让我们看看支持向量机
#============================================================ # 摇铃时间戳:2016-03-25 18:22:56 x86_64-w64-mingw32 #支持向量机。kernlab包提供了ksvm函数。图书馆(kernlab静静地=真正的## ##加载包:'kernlab' ## ##下面的对象从'package:ggplot2'中屏蔽:## ## alpha#建立支持向量机模型。set.seed(crv种子美元)MYksvmksvm(as.factor(状态)~,data =MYtrain [c (MYinput MYtarget)],内核=“rbfdot”,prob.model =真正的)生成SVM模型的文本视图。MYksvm ##支持向量机对象类“ksvm”## ## SV类型:C-svc(分类)##参数:代价C = 1 ## ##高斯径向基核函数。##超参数:sigma = 0.365136817631195 ## ##支持向量数:2407 ## ##目标函数值:-2004.306 ##训练误差:0.017811 ##包含概率模型。耗时:42.91秒
线性模型
最后,让我们看看线性模型。
#============================================================ # 摇铃时间戳:2016-03-25 18:23:56 x86_64-w64-mingw32 #回归模型#建立回归模型。MYglm全球语言监测机构(状态~,data =MYtrain [c (MYinput MYtarget)],家庭=二项(链接=“分对数”))生成线性模型的文本视图。print(总结(MYglm)) ## ##调用:## glm(公式= STATUS ~ ., family =二项式(link = "logit"), ## data = MYtrain[c(MYinput, MYtarget)]) ## ##偏差残差:## Min 1Q Median 3Q Max ## -1.3245 -0.2076 -0.1564 -0.1184 3.4080 ## ##系数:##估计Std错误z值Pr(>|z|) ##(拦截)-893.51883 33.96609 -26.306 < 2e-16 *** #年龄0.21944 0.00438 50.095 < 2e-16 *** # length_of_service -0.43146 0.01086 -39.738 < 2e-16 *** #性别fullmale 0.51900 0.06766 7.671 1.7e-14 STATUS_YEAR 0.44122 0.01687 26.148 < 2e-16 *** # BUSINESS_UNITSTORES -2.73943 0.16616 -16.486 < 2e-16 *** #符号。代码:0 '***' 0.001 '**' 0.01 '*' 0.05 '。' 0.1 ' ' 1## ## (Dispersion parameter for binomial family taken to be 1) ## ## Null deviance: 11920.1 on 44691 degrees of freedom ## Residual deviance: 9053.3 on 44686 degrees of freedom ## AIC: 9065.3 ## ## Number of Fisher Scoring iterations: 7猫(sprintf(Log可能性:%。3f (%d df)\n",logLik(MYglm) [1),attr(logLik (MYglm),“df”))) ##日志可能性:-4526.633 (6 df)猫(sprintf("零/剩余偏差差:%。3f (%d df)\n", MYglm$ Null . devim -MYglm$ devim, MYglm$df. Null -MYglm$df. Residual)) ## Null/剩余偏差差:2866.813 (5 df)猫(sprintf(“卡方p值:%.8f\n”,dchisq(MYglm$null.deviance-MYglm$deviance, MYglm$df.null-MYglm$df.residual)) ##卡方p值:0.00000000猫(sprintf("伪R-Square(乐观):%.8f\n", cor(MYglm$y, MYglm$ fitting .values))) ##伪R-Square(乐观):0.38428451猫('\n==== ANOVA ====\n\n') ## ## ==== anova ====print(方差分析(MYglm测试=“Chisq”)) ##偏差表分析## ##模型:二项式,链接:logit ## ##响应:STATUS ## ##按顺序添加的术语(从第一个到最后一个)## ## ## Df偏差残留物。Df渣油。Dev Pr(>Chi) ## NULL 44691 11920.1 ## age 1 861.75 44690 11058.3 < 2.2e-16 *** # length_of_service 1 1094.72 44689 9963.6 < 2.2e-16 *** # gender_full 1 14.38 44688 9949.2 0.0001494 STATUS_YEAR 1 716.39 44687 9232.8 < 2.2e-16 *** # BUSINESS_UNIT 1 179.57 44686 9053.3 < 2.2e-16 *** #符号。代码:0 '***' 0.001 '**' 0.01 '*' 0.05 '。' 0.1 ' ' 1猫(“\ n”)#耗时:1.62秒
这些只是这些模型的简单运行。在评价这些模型时,我们有办法在共同的基础上比较它们的结果。
评估模型
在评估模型的步骤中,我们能够回答开始时提出的最后2个原始问题:
我们能预测吗?
一句话“是的”。
我们能预测得多好?
用两个词“相当好”。
当涉及到评估预测类别的模型时,我们将精度定义为模型预测实际类别的次数。我们对很多东西都感兴趣。
第一个是误差矩阵。在误差矩阵中,您将实际结果与预测结果交叉制表。如果预测是100%的“完美”,那么每个预测都将与实际相同。这种情况几乎从未发生过。正确预测率越高,错误率越低越好。
误差矩阵
决策树
#============================================================ # 摇铃时间戳:2016-03-25 18:50:22 x86_64-w64-mingw32 #评估模型的性能。#为决策树模型生成错误矩阵#从决策树模型中获取响应。MYpr预测(MYrpartnewdata =MYtest [c(MYinput MYtarget)),类型=“类”)#生成显示计数的混淆矩阵。表格(MYtest[c(MYinput, MYtarget)]$STATUS, myypr,款=c(“实际”、“预测”)) ##预测##实际主动终止##主动4799 0 ##终止99 63#生成显示比例的混淆矩阵。pcme表格(实际,cl) ncnrow(x)台cbind(x /长度(实际)错误=酸式焦磷酸钠(1:数控,函数(右)轮(总和(r - r) (x) /总和(x [r]),2)))名称(attr(资源描述,“dimnames”))c(“实际”、“预测”)返回(tbl)}每pcme(MYtest[c(MYinput, MYtarget)]$STATUS, myypr)轮(每2) ##预测##实际主动终止错误##主动0.97 0.00 0.00 ##终止0.02 0.01 0.61#计算整体错误百分比。猫(One hundred.* (1-sum(诊断接头(/),na.rm =真正的),2(2#计算平均类错误百分比。猫(One hundred.*轮(意思是(每,“错误”),na.rm =真正的),2)) ## 30
演算法
为Ada Boost模型生成错误矩阵#从Ada Boost模型获得响应。MYpr预测(MYadanewdata =MYtest [c(MYinput MYtarget)])#生成显示计数的混淆矩阵。表格(MYtest[c(MYinput, MYtarget)]$STATUS, myypr,款=c(“实际”、“预测”)) ##预测##实际主动终止##主动4799 0 ##终止99 63#生成显示比例的混淆矩阵。pcme表格(实际,cl) ncnrow(x)台cbind(x /长度(实际)错误=酸式焦磷酸钠(1:数控、功能(r)轮(总和(r - r) (x) /总和(x [r]),2)))名称(attr(资源描述,“dimnames”))c(“实际”、“预测”)返回(tbl)}每pcme(MYtest[c(MYinput, MYtarget)]$STATUS, myypr)轮(每2) ##预测##实际主动终止错误##主动0.97 0.00 0.00 ##终止0.02 0.01 0.61#计算整体错误百分比。猫(One hundred.*轮(1-sum(诊断接头(/),na.rm =真正的),2(2#计算平均类错误百分比。猫(One hundred.*轮(意思是(每,“错误”),na.rm =真正的),2)) ## 30
随机森林
#生成随机森林模型的错误矩阵从随机森林模型中获取响应。MYpr预测(MYrfnewdata =na.omit(MYtest [c(MYinput MYtarget))))#生成显示计数的混淆矩阵。表(na.omit(MYtest[c(MYinput, MYtarget])]$STATUS, myypr,款=c(“实际”、“预测”)) ##预测##实际主动终止##主动4799 0 ##终止99 63#生成显示比例的混淆矩阵。pcme表格(实际,cl) ncnrow(x)台cbind(x /长度(实际)错误=酸式焦磷酸钠(1:数控、功能(r)轮(总和(r - r) (x) /总和(x [r]),2)))名称(attr(资源描述,“dimnames”))c(“实际”、“预测”)返回(tbl)}每pcme(MYtest[c(MYinput, MYtarget)]$STATUS, myypr)轮(每2) ##预测##实际主动终止错误##主动0.97 0.00 0.00 ##终止0.02 0.01 0.61#计算整体错误百分比。猫(One hundred.*轮(1-sum(诊断接头(/),na.rm =真正的),2(2#计算平均类错误百分比。猫(One hundred.*轮(意思是(每,“错误”),na.rm =真正的),2)) ## 30
支持向量模型
为SVM模型生成一个误差矩阵。#从SVM模型中获得响应。MYpr预测(MYksvmnewdata =na.omit(MYtest (c (MYinput MYtarget))))#生成显示计数的混淆矩阵。表(na.omit(MYtest[c(MYinput, MYtarget])]$STATUS, myypr,款=c(“实际”、“预测”)) ##预测##实际主动终止##主动4799 0 ##终止150 12#生成显示比例的混淆矩阵。pcme表格(实际,cl) ncnrow(x)台cbind(x /长度(实际)错误=酸式焦磷酸钠(1:数控、功能(r)轮(总和(r - r) (x) /总和(x [r]),2)))名称(attr(资源描述,“dimnames”))c(“实际”、“预测”)返回(tbl)}每pcme(MYtest[c(MYinput, MYtarget)]$STATUS, myypr)轮(每2) ##预测##实际主动终止错误##主动0.97 0 0.00 ##终止0.03 0 0.93#计算整体错误百分比。猫(One hundred.*轮(1-sum(诊断接头(/),na.rm =真正的),2(3#计算平均类错误百分比。猫(One hundred.*轮(意思是(每,“错误”),na.rm =真正的),246 .
线性模型
为线性模型生成一个错误矩阵。从线性模型中获得响应。MYpras.vector (ifelse(预测(MYglm类型=格林:“响应”,newdata =MYtest [c(MYinput, MYtarget)) >0.5绿色:“终止”、“活跃”))#生成显示计数的混淆矩阵。表(na.omit(MYtest[c(MYinput, MYtarget])]$STATUS, myypr,款=c(“实际”、“预测”) ##预测##实际主动##主动4799 ##终止162#生成显示比例的混淆矩阵。pcme表格(实际,cl) ncnrow(x)台cbind(x /长度(实际)错误=酸式焦磷酸钠(1:数控、功能(r)轮(总和(r - r) (x) /总和(x [r]),2)))名称(attr(资源描述,“dimnames”))c(“实际”、“预测”)返回(tbl)}每pcme(MYtest[c(MYinput, MYtarget)]$STATUS, myypr)轮(每2) ##预测##实际主动错误##主动0.97 0 ##终止0.03#计算整体错误百分比。猫(One hundred.*轮(1-sum(诊断接头(/),na.rm =真正的),2) ## -97#计算平均类错误百分比。猫(One hundred.*轮(意思是(每,“错误”),na.rm =真正的),2))
这很有趣!
总结混淆矩阵表明,决策树、随机森林和Adaboost的预测都相似。但支持向量机和线性模型在这些数据上表现更差。
曲线下面积(AUC)
另一种评估模型的方法是AUC。AUC越高越好。下面的代码生成生成图形所需的信息。
#============================================================ # 摇铃时间戳:2016-03-25 19:44:22 x86_64-w64-mingw32 #评估模型的性能。# ROC曲线:需要ROCR包。图书馆(ROCR) ##加载所需的包:gplots ## ##加载包:'gplots' ## ##下面的对象从'package:stats'中屏蔽:## ## lowess# ROC曲线:需要ggplot2包。图书馆(ggplot2静静地=真正的)#在MFG10YearTerminationData [test]上为rpart模型生成ROC曲线。MYpr预测(MYrpartnewdata =MYtest [c(MYinput MYtarget)]),2]#移除缺失目标的观测值。no.missna.omit(MYtest[c(MYinput, MYtarget)]$STATUSattr(no.miss“na.action”)属性(no.miss)如果(长度(miss.list)) {pred预测(MYpr[小姐。列表),no.miss)} else { pred预测(我的,不,小姐)}pe性能(pred“tpr”、“玻璃钢”非盟)性能(pred“auc”) @y.values [[1]] pddata.frame(玻璃钢=unlist((电子邮件保护)),tpr =unlist((电子邮件保护)p))ggplot(帕金森病,aes(x =玻璃钢,y =Tpr)) p geom_line(颜色=“红色”) pxlab> (“假阳性率”) +ylab(“真阳性率”) pggtitle(“ROC曲线决策树MFG10YearTerminationData[测试]STATUS”) p主题(plot.title =element_text(大小=10p))geom_line(data =data.frame(),aes(x =c(0 1),y = c(0 1)),颜色=“灰色”) p注释(“文本”,x =0.50y =0.00hjust =0vjust =0、大小=5,标签=粘贴(" AUC = ",轮(非盟,2)))打印(p)
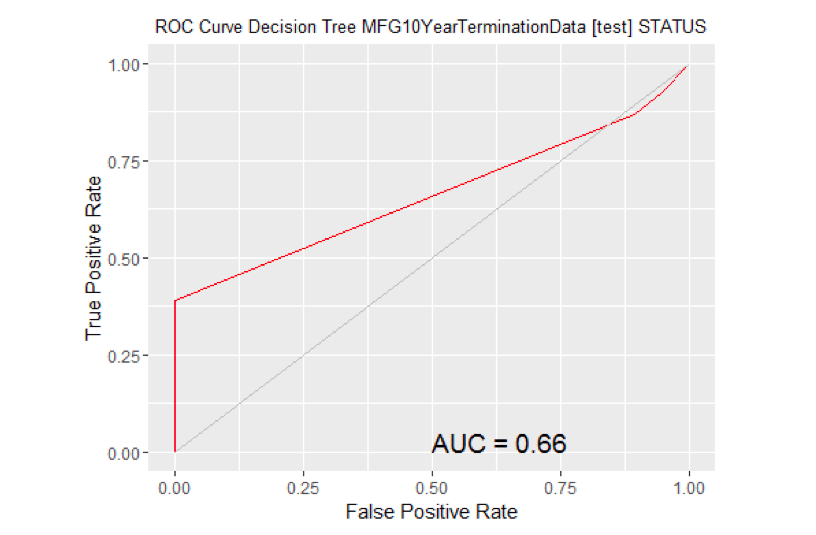
计算曲线下的面积。#移除缺失目标的观测值。no.missna.omit(MYtest[c(MYinput, MYtarget)]$STATUSattr(no.miss"na.action”)属性布朗(no.miss)零如果(长度(miss.list)) {pred预测(MYpr[小姐。列表),no.miss)} else { pred预测(myypr, no.miss)}性能(pred“auc”) # #一个对象类的“性能”# #槽“x.name”:# #[1]”没有“# # # #槽“y.name”:# #[1]“ROC曲线下的面积”# # # #槽“alpha.name”:# #[1]”没有“# # # #槽“x.values”:# #列表()# # # #槽“y.values”:# # # # ([1])0.6619685 [1] ## ## ## “阿尔法。values": ## list() # ROC曲线:需要ROCR包。图书馆(ROCR)# ROC曲线:需要ggplot2包。图书馆(ggplot2静静地=真正的)#在MFG10YearTerminationData [test]上生成ada模型的ROC曲线。MYpr < -预测(MYadanewdata =MYtest [c(MYinput MYtarget)),类型=“概率”) (2]#移除缺失目标的观测值。no.missna.omit(MYtest[c(MYinput, MYtarget)]$STATUSattr(no.miss“na.action”)属性布朗(no.miss)零如果(长度(miss.list)) {pred预测(MYpr[小姐。列表),no.miss)} else { pred预测(我的,不,小姐)}pe性能(pred“tpr”、“玻璃钢”非盟)性能(pred“auc”) @y.values [[1]] pddata.frame(玻璃钢=unlist((电子邮件保护)),tpr =unlist((电子邮件保护)p))ggplot(帕金森病,aes(x =玻璃钢,y =Tpr)) p geom_line(颜色=“红色”) pxlab> (“假阳性率”) +ylab(“真阳性率”) pggtitle(“ROC曲线Ada Boost MFG10YearTerminationData[测试]STATUS”) p主题(plot.title =element_text(大小=10p))geom_line(data =data.frame(),aes(x =c(0 1),y = c(0 1)),颜色=“灰色”) p注释(“文本”,x =0.50y =0.00hjust =0vjust =0、大小=5,标签=粘贴(" AUC = ",轮(非盟,2)))打印(p)
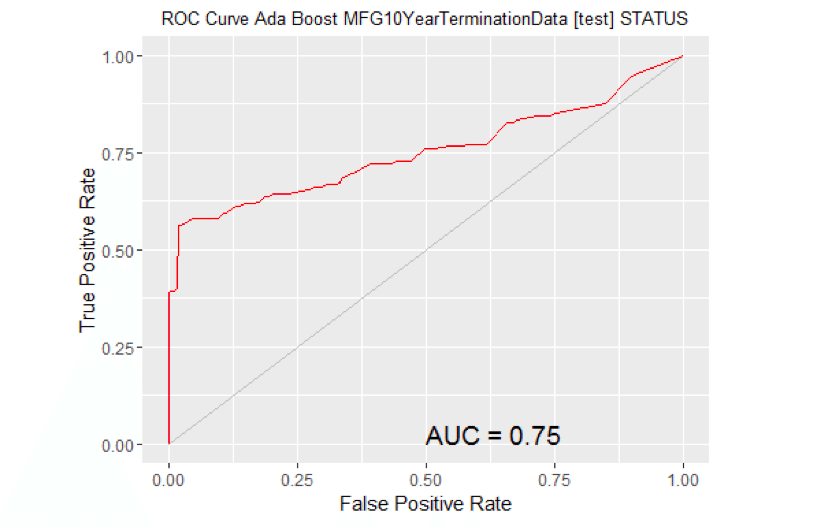
计算曲线下的面积。#移除缺失目标的观测值。no.missna.omit(MYtest[c(MYinput, MYtarget)]$STATUSattr(no.miss"na.action”)属性布朗(no.miss)零如果(长度(miss.list)) {pred预测(MYpr[小姐。列表),no.miss)} else { pred预测(myypr, no.miss)}性能(pred“auc”) # #一个对象类的“性能”# #槽“x.name”:# #[1]”没有“# # # #槽“y.name”:# #[1]“ROC曲线下的面积”# # # #槽“alpha.name”:# #[1]”没有“# # # #槽“x.values”:# #列表()# # # #槽“y.values”:# # # # ([1])0.7525726 [1] ## ## ## “阿尔法。## list()# ROC曲线:需要ROCR包。图书馆(ROCR)# ROC曲线:需要ggplot2包。图书馆(ggplot2静静地=真正的#在MFG10YearTerminationData [test]上生成rf模型的ROC曲线。MYpr < -预测(MYrfnewdata =na.omit(MYtest [c(MYinput, MYtarget)]), type=“概率”) (2]#移除缺失目标的观测值。no.miss<-na.omit(na。省略(MYtest[c(MYinput, MYtarget)])$STATUS) miss.list <-attr(no.miss“na.action”)属性布朗(no.miss)零如果(长度(miss.list)) pred <-预测(MYpr[小姐。列表),no.miss)} else { pred <-预测(myypr, no.miss)} pe <-性能(pred“tpr”、“玻璃钢”) au <-性能(pred“auc”) @y.values [[1]] pd <-data.frame(玻璃钢=unlist((电子邮件保护)),tpr =unlist((电子邮件保护))) p <-ggplot(帕金森病,aes(x =玻璃钢,y =Tpr)) p <-geom_line(颜色=“红色”) p <-xlab> (“假阳性率”) +ylab(“真阳性率”) p <-ggtitle(“ROC曲线随机森林MFG10YearTerminationData [test] STATUS”) p <-主题(plot.title =element_text(大小=10)) p <-geom_line(data =data.frame(),aes(x =c(0 1),y = c(0 1)),颜色=“灰色”) p <-注释(“文本”,x =0.50y =0.00hjust =0vjust =0、大小=5,标签=粘贴(" AUC = ",轮(非盟,2)))打印(p)
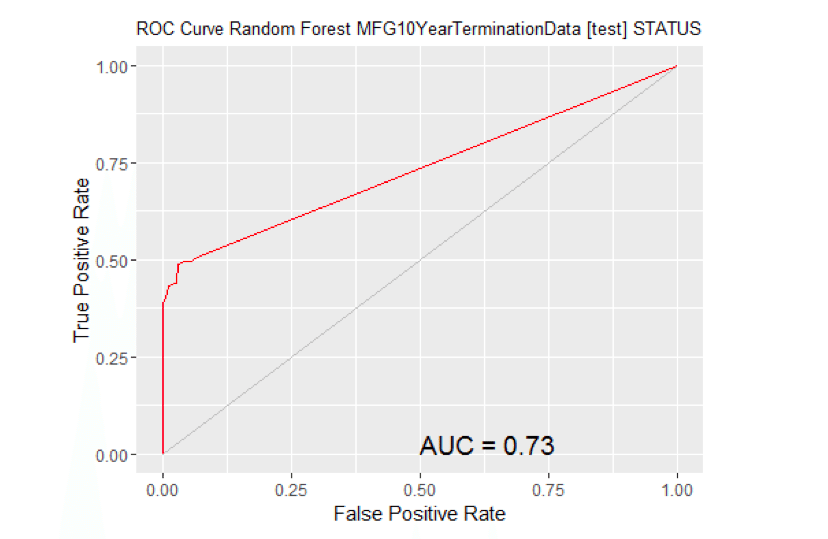
计算曲线下的面积。#移除缺失目标的观测值。no.miss<-na.omit (na.omit(MYtest[c(MYinput, MYtarget)])$STATUS) miss.list <-attr(no.miss"na.action”)属性(no.miss) < -零如果(长度(miss.list)) {pred <-预测(MYpr[小姐。列表),no.miss)} else { pred <-预测(myypr, no.miss)}性能(pred“auc”) # #一个对象类的“性能”# #槽“x.name”:# #[1]”没有“# # # #槽“y.name”:# #[1]“ROC曲线下的面积”# # # #槽“alpha.name”:# #[1]”没有“# # # #槽“x.values”:# #列表()# # # #槽“y.values”:# # # # ([1])0.7332874 [1] ## ## ## “阿尔法。## list()# ROC曲线:需要ROCR包。图书馆(ROCR)# ROC曲线:需要ggplot2包。图书馆(ggplot2静静地=真正的)#在MFG10YearTerminationData [test]上生成ksvm模型的ROC曲线。MYpr <- kernlab::预测(MYksvmnewdata =na.omit(MYtest [c (MYinput MYtarget)]),类型=“概率”) (2]#移除缺失目标的观测值。no.miss<-na.omit(na.omit(MYtest[c(MYinput, MYtarget)])$STATUS) miss.list <-attr(no.miss“na.action”)属性布朗(no.miss)零如果(长度(miss.list)) {pred <-预测(MYpr[小姐。列表),no.miss)} else { pred <-预测(myypr, no.miss)} pe <-性能(pred“tpr”、“玻璃钢”) au <-性能(pred“auc”) @y.values [[1]] pd <-data.frame(玻璃钢=unlist((电子邮件保护)),tpr =unlist((电子邮件保护))) p <-ggplot(帕金森病,aes(x =玻璃钢,y =Tpr)) p <-geom_line(颜色=“红色”) p <-xlab> (“假阳性率”) +ylab(“真阳性率”) p <-ggtitle(ROC曲线支持向量机MFG10YearTerminationData[测试]STATUS) p <-主题(plot.title =element_text(大小=10)) p <-geom_line(data =data.frame(),aes(x =c(0 1),y = c(0 1)),颜色=“灰色”) p <-注释(“文本”,x =0.50y =0.00hjust =0vjust =0、大小=5,标签=粘贴(" AUC = ",轮(非盟,2)))打印(p)
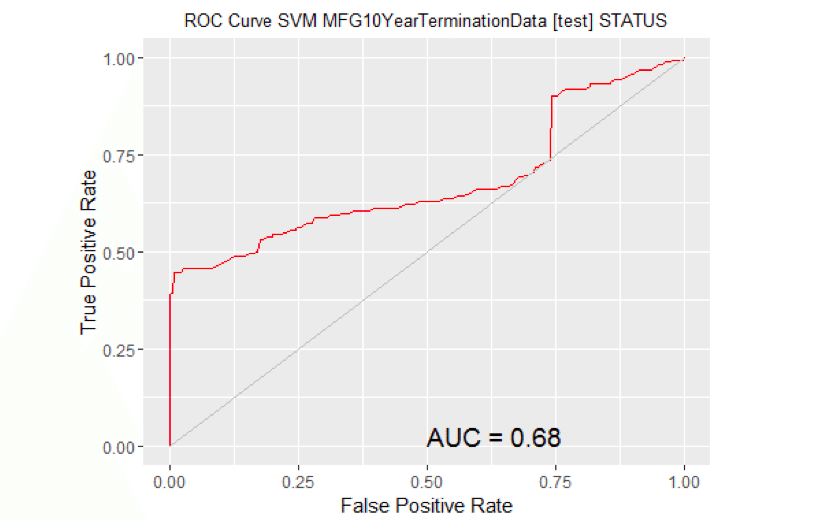
计算曲线下的面积。#移除缺失目标的观测值。no.miss<-na.omit (na.omit(MYtest[c(MYinput, MYtarget)])$STATUS) miss.list <-attr(no.miss"na.action”)属性(no.miss) < -零如果(长度(miss.list)) {pred <-预测(MYpr[小姐。列表),no.miss)} else { pred <-预测(myypr, no.miss)}性能(pred“auc”) # #一个对象类的“性能”# #槽“x.name”:# #[1]”没有“# # # #槽“y.name”:# #[1]“ROC曲线下的面积”# # # #槽“alpha.name”:# #[1]”没有“# # # #槽“x.values”:# #列表()# # # #槽“y.values”:# # # # ([1])0.679458 [1] ## ## ## “阿尔法。## list()# ROC曲线:需要ROCR包。图书馆(ROCR)# ROC曲线:需要ggplot2包。图书馆(ggplot2静静地=真正的)#在MFG10YearTerminationData [test]上生成glm模型的ROC曲线。MYpr < -预测(MYglm类型=“响应”newdata = MYtest [c(MYinput MYtarget)])#移除缺失目标的观测值。no.miss<-na.omit(MYtest[c(MYinput, MYtarget)]$STATUS) miss.list <-attr(no.miss“na.action”)属性布朗(no.miss)零如果(长度(miss.list)) {pred <-预测(MYpr[小姐。列表),no.miss)} else { pred <-预测(myypr, no.miss)} pe <-性能(pred“tpr”、“玻璃钢”) au <-性能(pred“auc”) @y.values [[1]] pd <-data.frame(玻璃钢=unlist((电子邮件保护)),tpr =unlist((电子邮件保护))) p <-ggplot(帕金森病,aes(x =玻璃钢,y =Tpr)) p <-geom_line(颜色=“红色”) p <-xlab> (“假阳性率”) +ylab(“真阳性率”) p <-ggtitle(“ROC曲线线性MFG10YearTerminationData [test] STATUS”) p <-主题(plot.title =element_text(大小=10)) p <-geom_line(data =data.frame(),aes(x =c(0 1),y = c(0 1)),颜色=“灰色”) p <-注释(“文本”,x =0.50y =0.00hjust =0vjust =0、大小=5,标签=粘贴(" AUC = ",轮(非盟,2)))打印(p)
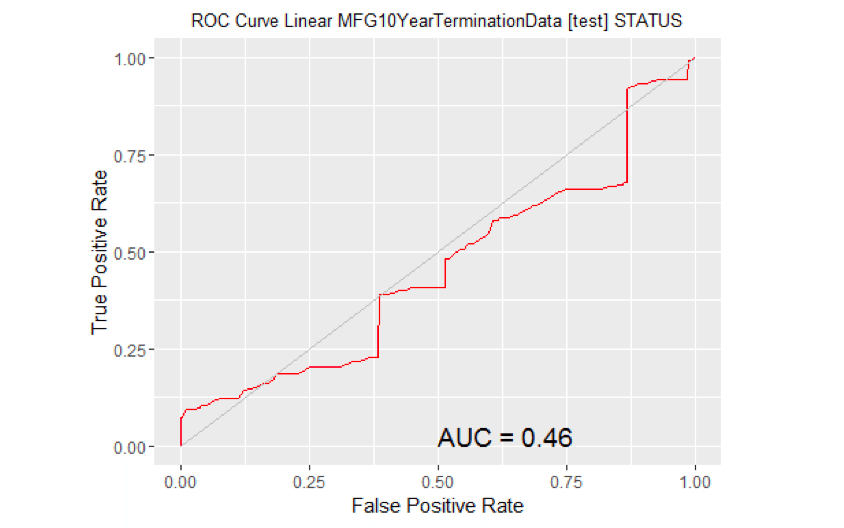
计算曲线下的面积。#移除缺失目标的观测值。no.miss<-na.omit(MYtest[c(MYinput, MYtarget)]$STATUS) miss.list <-attr(no.miss"na.action”)属性(no.miss) < -零如果(长度(miss.list)) {pred <-预测(MYpr[小姐。列表),no.miss)} else { pred <-预测(myypr, no.miss)}性能(pred“auc”) # #一个对象类的“性能”# #槽“x.name”:# #[1]”没有“# # # #槽“y.name”:# #[1]“ROC曲线下的面积”# # # #槽“alpha.name”:# #[1]”没有“# # # #槽“x.values”:# #列表()# # # #槽“y.values”:# # # # ([1])0.4557386 [1] ## ## ## “阿尔法。## list()
有几件事需要注意:
- Adaboost模型的AUC最高。因此,我们将用它来预测2016年的终结。
- 线性模型是最差的。
目前成果和文件
本文的所有文件(代码、csv数据文件和已发布的格式)可以在以下位置找到必威 官方网站链接.
结果是使用R Markdown语言呈现的。这篇文章写在里面。它是限制型心肌病链接中提供的文件。R Markdown允许将R代码、结果和图表与本文的文本材料内联集成。必威 官方网站它可以以Word、HTML或PDF格式发布。
如果您想运行本文中的任何代码,您需要下载CSV文件,并更改R代码中的路径信息,以适应您定位CSV文件的位置。
部署模型
让我们来预测2016年的终结。
在现实生活中,你会对2015年底活跃员工的数据进行快照。为了本练习的目的,我们将这样做,但也将更改数据,使服务年龄和年份信息- 2016年大1年。
#应用模型#生成2016年数据Employees2016# 2015的数据ActiveEmployees2016 < -子集(Employees2016状态= =“活跃”) ActiveEmployees2016年龄< -ActiveEmployees2016美元时代+1ActiveEmployees2016 length_of_service < -ActiveEmployees2016 length_of_service美元+1#MYada是我们之前给adaboost模型起的名字ActiveEmployees2016 PredictedSTATUS2016 < -美元预测(ActiveEmployees2016 MYada PredictedTerminatedEmployees2016 < - - - - - -子集(ActiveEmployees2016 PredictedSTATUS2016 = =“终止”)#显示前5次预测的记录头(PredictedTerminatedEmployees2016) ## EmployeeID recorddate_key birthdate_key orighiredate_key ## 1551 1703 12月31日0:00 1951-01-13 1990-09-23 ## 1561 1705 12月31日0:00 1951-01-20 1990-09-27 ## 1581 1710 12月31日0:00 1951-01-27 1990-09-29 ## 1600 1713 12月31日0:00 1951-01-27 1990-10-01 ## 1611 1715 12月31日0:00 1951-01-31 1990-10-03 ## terminationdate_key年龄长度_of_service city_name ## 1551 1900-01-01 65 26温哥华## 15611900-01-01 65里士满26 # # 1571 1900-01-01 65 26基隆拿# # 1581 1900-01-01 65 1600年乔治王子城# # 26日1900-01-01 65温哥华26 # # 1611 1900-01-01 65里士满26 # # department_name job_title store_name gender_short # # 1551肉类肉经理43 F # # 1561肉类肉经理29 # # 1571肉切肉机16 # # 1581客户服务客户服务经理26 # # 1600生产生产经理43 # # 1611生产生产经理29 F # # gender_full termreason_desc termtype_descSTATUS_YEAR STATUS ## 1551女不适用不适用2015 ACTIVE ## 1561男不适用不适用2015 ACTIVE ## 1581男不适用不适用2015 ACTIVE ## 1600女不适用不适用2015 ACTIVE ## 1611女不适用不适用2015 ACTIVE ## BUSINESS_UNIT PredictedSTATUS2016 ## 1551门店终止## 1561门店终止## 1571门店终止## 1581门店终止##1611家门店被终止
2016年预计有93例妊娠终止。
总结
这篇博客文章的意图是:必威 官方网站
- 再次演示使用R的People Analytics示例
- 从人力资源环境中展示一个有意义的例子
- 不一定是一个最佳实践的例子,而是一个说明性的例子
- 激励人力资源社区更广泛地使用“数据驱动”的人力资源决策。
- 鼓励那些对在数据科学中使用R感兴趣的人更深入地研究R在这一领域的工具。
从实际的角度来看,如果这是来自真实组织的真实数据,那么重点将是组织对数据告诉他们的内容做出“决策”。没有这样做的能力就是所谓的分析瘫痪.
如果你想了解更多关于在R中进行人力资源分析的知识,包括流失分析、参与度分析、数据可视化等,请查看我们的课程预测分析在必威手机网页.

你准备好迎接HR的未来了吗?
在线学习现代和相关的人力资源技能
