第2部分你应该知道的9个(HR)分析术语

你知道你的数据科学家使用的所有术语吗?很多人对学习统计学和机器学习中涉及的技术术语感兴趣第1部分.多变量分析、随机森林和算法提升这些词到底是什么意思?在这篇文章中,我们将告诉你——并向你展示——关于它的一切!
1.多变量分析
多变量分析与单变量分析相反。单变量分析只有一个所谓的Y变量。Y变量也被称为因变量或结果变量。例如,当你想要预测年龄和敬业程度如何影响某人的绩效评级时,只有一个因变量。然而,当你想预测某人的绩效评级和薪酬时,有两个因变量,因此是多元分析
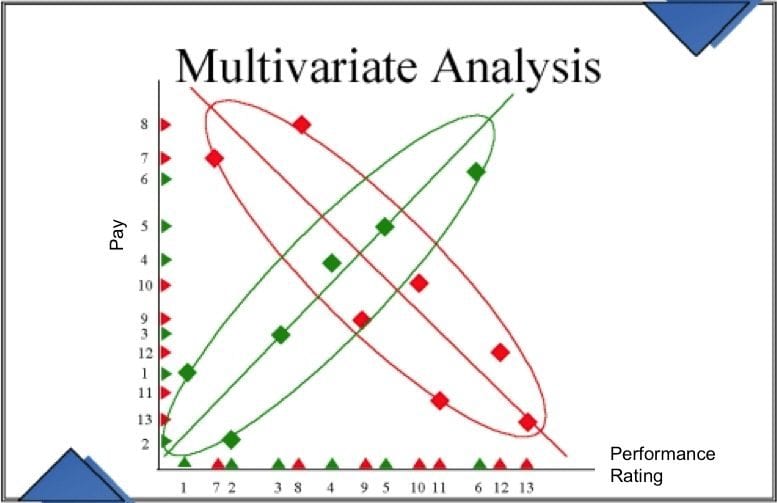
2.依赖的vs.独立的
当你想要预测敬业度如何影响绩效时,你会认为绩效取决于员工的敬业度。因此,敬业度是自变量,而绩效是因变量。你期望因变量依赖于自变量的分数,所以当你操纵自变量(敬业度增加/减少)时,你也期望因变量会改变(绩效增加/减少)。
3.提高
当你创建一个算法时,你希望它尽可能具有预测性和准确性。Boosting是一种交互式统计技术,可以创建多个额外的数据训练数据集。为每个数据集创建一个模型。这些数据集是有意创建的(即非随机的)。这意味着错误分类的数据点的权重增加了,因此下一个算法将更好地拟合这些错误分类。这个过程会重复很多次。这些模型一起决定最有可能的结果。他们根据加权投票做出决定,在加权投票中,更准确的模型比不准确的模型拥有更多的投票权。
相关:了解更多招聘指标
相关(免费)资源!继续往下读↓
51人力资源指标备忘单
数据驱动的人力资源从实施相关的人力资源指标开始。下载51个人力资源指标的免费小抄
Boosting是多个算法的组合,通常被称为元算法。最著名的增强分类器是AdaBoost(用于这是林登的必威 官方网站博客).这些模型的结果比较复杂,因此难以分析,而元算法具有很好的性能。
4.装袋
Bagging是另一种元算法,代表Bootstrap聚合。Bagging是一种基于原始数据集对多个训练集进行独立采样的技术。多个模型建立在这些额外数据集的基础上,并增加了这些数据集的大小——就像增强一样。预测最终由不同模型的非加权多数投票做出。
Bagging有助于减少算法中异常值的影响,从而减少算法的方差。这种技术主要用于决策树算法,因为一个异常值可以创建一个完全不同的决策树。因此,它的影响要比其他算法大得多。
5.C4.5
C4.5是一种决策树算法。C4.5是一种著名的非常精确的数据挖掘算法。对于每个新的分支,C4.5使用每个属性的信息增益与默认增益比的标准,然后选择最好的属性来分割它的分支。
相关:概述人力资源指标
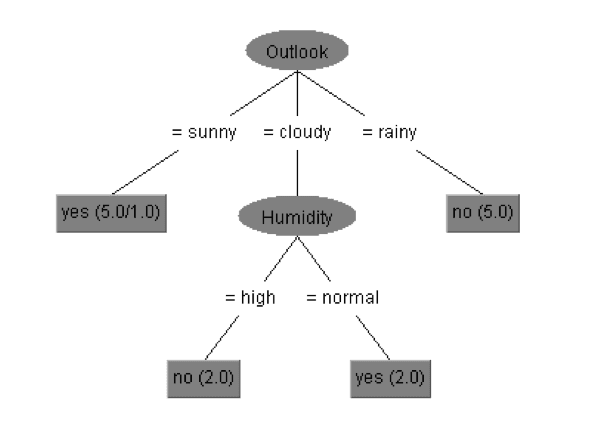
下面的树显示了两个天气变量,以及它们如何影响你的邻居在随机一天打高尔夫球的机会(结果被激活为是和否)。它表明C4.5产生的输出非常容易理解和可视化。这棵树表明,当天气前景是晴天时,你的邻居更有可能打高尔夫球,而不是雨天。对于一个阳光明媚的前景,该模型预测你的邻居打高尔夫球的概率(结果是)六次中有五次正确(决策结果中的5.0/1.0注释)。
6.修剪
你还不理解这个决策树吗?这很有可能!在这一段中,我们将更清楚地说明这一点。剪枝是一种用于降低决策树复杂性的技术。决策树是通过使用最具解释性的属性来分割其分支来构建的,这个过程一直持续到树完成为止。然而,这样的树可能又大又复杂。修剪是对整棵树的所有分支进行统计测试的过程。当统计置信因子过低时,将删除特定的分支(因此:修剪)。一个简单的决策树不容易过度拟合.当树变得非常详细,以至于它(几乎)完美地适合特定的数据集时,就会发生过拟合。在这种情况下,当添加更多的数据时,算法的准确性会降低。
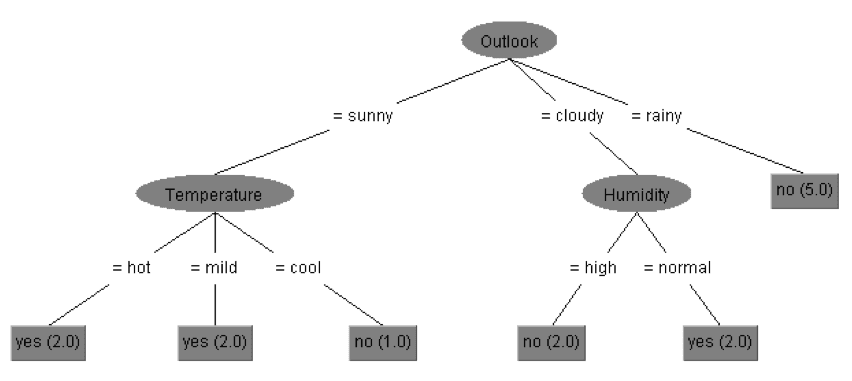
这和我们上面展示的决策树是一样的,但是,这一棵没有修剪。正如你所看到的,这棵树将阳光前景分为三个不同的温度类别,变得非常具体。它们很好地拟合了数据,但存在过拟合的风险。这表明,当你比较准确率时:修剪模型的准确率为92%,而未修剪的模型与数据完美吻合。
7.随机森林
与增强技术不同,随机森林技术随机化算法而不是数据。通常,决策树算法选择最好的属性来分割它的分支。然而,在随机森林中,选择最佳属性的过程是随机的。这会产生不同的决策树(因此是森林)。这些随机树一起产生更好的结果。
8.线性回归
线性回归分析是一种估计因变量与一个或多个自变量之间关系的统计方法。回归分析使用最小二乘法在数据上估计最佳拟合曲线。这条曲线可以用来预测各种结果。要阅读一些使用线性回归的示例和业务案例,请勾选这个博客必威 官方网站.
9.数据清理
数据清理是人力资源分析中一个众所周知的主题。这是什么意思?数据清理是检查数据、修复不一致和收集缺失数据以便为分析做准备的过程。人力资源数据通常被认为是“肮脏的”。脏数据有各种各样的定义:数据的某些部分可能缺失,相同的作业可能有不同的标签,因此不容易识别它们,在多个系统中可能有同一个人的多个不对应的记录,等等。“脏数据”在跨国公司尤其屡屡出现。这些公司通常使用不同国家的不同系统来记录相同的数据。只要数据采集程序稍有不同,数据就会不一致。
本博客是你必威 官方网站应该知道的9个人力资源分析术语系列的第2部分。你可以阅读第一部分在这里.第1部分包括数据挖掘、机器学习和监督学习等术语。如果你想让我们在后续博客中解释更多术语,请在评论中告诉我们!必威 官方网站

埃里克·范·沃彭
埃里克·范·沃彭是AIHR的创始人和院长。他是一位通过将技术创新引入人力资源环境来塑造现代人力资源实践的专家。他是全球公认的人力资源思想领袖,经常就人才分析、数字人力资源和工作的未来等主题发表演讲。
你准备好迎接HR的未来了吗?
在线学习现代和相关的人力资源技能
